6/ Evaluation pathway
Résumé:
Le Life Cycle Inventory Assessment (LCIA) est l’étape d’évaluation et de normalisation des pathways.
Lors de l’évaluation des pathways, la diversité des natures des informations impose plusieurs cas:
La méthode calcul() transforme les variables d’entrées en impact potentiel absolu non représentatif, selon une relation causale définit mathématiquement.
La méthode estimate() transforme des notations relatives d’impacts potentiels en impact potentiel.
L’étape de normalisation va transformer les valeurs précédentes en impact réel effective sur une capabilité du modèle de valeur. Ces impacts sont positives et non nulles. Elles représentent l’appréciation (Impact > 100%) ou la dépréciation (Impact < 100%) d’une capabilité par rapport à une situation de référence.
0/ Introduction: évaluer des impacts
L’objectif de cette partie est d’utiliser les valeurs collectées dans l’inventaire du cycle de vie (LCI) du projet afin d’évaluer l’impact du projet sur le modèle de valeur du projet.* C’est une partie plus calculatoire et statistique que les deux parties précédentes. C’est donc au cœur du code de l’application Donut.
De la même manière qu’en ACV environnementale, nous allons chercher à relier des variables avec des impacts connus (par exemple des émissions de micro plastiques avec un impact sur la santé humaine, ou encore une pratique sociale permise par une infrastructure avec une amélioration de l’implication politique à l’échelle du quartier). Cependant, les impacts sociaux dépendent du contexte, il est alors nécessaire d’introduire des descripteurs du contexte comme données d’entrées pour garder une consistance méthodologique. Hélas, comme toutes les données contextuelles et sociales ne sont pas forcément quantifiables, et sont même souvent subjective, les relations qui relient variables et impacts ne peuvent pas être déduite facilement.
C’est pourquoi au cours des 20 dernières années, un nombre importants de recherchent ont été effectuées, qui l’ont peut classer en trois tendances [1] :
L’ACV sociale des attributs (« performance » de l’entreprise, dans la continuité RSE).
L’analyse des « pathways » (recherche des relations statistiques entre des facteurs et des impacts).
L’ACV des capabilités, avec un rapprochement méthodologique vers les pathways.
Les deux premières méthodes ont l’avantage d’être facilement explicable et simple. La première, résumé grossièrement, vise à évaluer les performances actuelles d’une entreprise par un système de notation subjectif (souvent) afin d’en déduire les leviers d’actions pour le futur. C’est une analyse statique, figée dans le temps. Nous nous éloignerons de cette piste qui ne prend pas en compte les tendances, l’évolution du contexte, les effets rebonds et les déplacements d’impact. la deuxième méthode est une analyse doté d’une théorie scientifique bien plus « dure »,: un modèle rodé par de nombreuses recherches et expériences qui caractérisent une relation que l’on avait pressentit. Ce modèle est bien plus rationnel et complexe, se rapprochant de modèles prescriptifs. Le manque de recherchent sur les indicateurs sociaux bloque néanmoins son usage. En effet, la nature non quantifiable de l’information traité oblige souvent à faire des raccourcis méthodologiques assez importants que ce modèle ne corrige pas, ou alors la recherche est simplement bloqué, et aucun consensus n’émerge sur une relation causale entre des variables et un impact.
La troisième tendance tente de prendre en compte la complexité et les défauts des deux tendances précédentes. Son parti pris est simple : assumer la complexité d’évaluation et la subjectivité qui en découle en intégrant les questionnements éthiques au cœur de sa méthodologie. Cela se traduit par une perception différente de l’ensemble de la méthodologie. Les AoP ne sont plus des données habituelles et facilement quantifiables, l’ACV des capabilités souhaite évaluer des impacts sur… les capabilités. Ce changement de décor permet d’éviter astucieusement certains écueils précédemment énoncer et la souplesse de l’évaluation par capabilité permet de piocher des points fort dans les deux précédentes méthodes.
Pour l’application du Donut, nous nous sommes très fortement inspirés de l’évaluation avec le prisme des capabilités, c’est un terme qui se rapproche des valeurs que nous partagions sur l’amélioration de l’autonomie des individus et les dépendances techniques.
Résumons, nous cherchons donc a évaluer des impacts potentiels effectifs sur différentes capabilités. Pour cela, nous devons caractériser les relations causales qui relient les variables du cycle de vie socio-économique et environnemental du projet avec des aires de protection (AoP). Ces aires de protection font parti d’un modèle de valeur, qui reflètent une éthique du projet acceptée par les parties prenantes, et qui caractérise les capabilités qui sont importantes.
1/ Les capabilités
1.1 Notion de capabilités
Cette notion philosophique vient du prix Nobel d’économie de 1998, Amartya Sen.

Ce dernier émet une double critique du welfarisme:
Il critique l’hypothèse de l’utilitarisme en revendiquant la diversité des humains et la hiérarchisation différentes de leurs préférences, par exemple en démontrant les écueils de la pyramide de Measlow, qu’il juge intéressante à son époque, dans son contexte occidental, mais sans valeur sur la nature de l’être humain en général.
Il critique l’indicateur de la consommation (qui affirme que la consommation amène à la satisfaction et donc au bien-être). Il prend en compte les composantes d’ordre non matériels dans la théorie qu’il développe.
Ces critiques l’ont amené a développé son concept de capabilités[2] , afin d’exprimer le bien être sans biais capitalistes ou réducteurs :
La capabilité d’une personne est définie comme l’étendue des possibilités réelles que possède un individu de faire et d’être.
En résumé, à partir de dotation (endowment/potentialité), un individu va chercher à convertir ses dotations en accomplissement à l’aide de fonction d’utilisation. L’image de ses dotations par la fonction d’utilisation est la capabilité de l’individu. L’accomplissement est la part des capabilités qui s’accomplissent.

Dans sa théorie, Sen démontre que l’égalité des Capabilités est un critère de justice essentiel. Les problèmes sociaux sont ainsi souvent expliqués non par l’absence de la ressource, mais comme une privation de capabilité (traduite par des dotations plus petites, des fonctions d’utilisations restreintes et de taux d’accomplissement plus faible.).
1.2 L’avantage de l’ACV des capabilités
Le choix de l’ACV sociale par capabilité vient partiellement relever le problème de la diversité des indicateurs. En effet, comme l’on a décidé d’évaluer l’impact comme un potentiel d’amélioration ou de dégradation des AoP définit, il est nécessaire de comparer la sortie (avec unité) d’un pathway avec une référence donnée (qui assure la même unité fonctionnelle, ce n’est donc pas nécessairement une référence nulle, mais cela peut être un scénario de référence ou une politique régionale). Cela à l’avantage d’homogénéiser les impacts avant même de chercher à les pondérer et analyser. On obtient ainsi une valeur sans unité qui reflète un vecteur d’impact d’un midpoint particulier. Chacun des AoP étant composé d’une panoplie de midpoints, il convient alors de sommer les vecteurs d’impacts potentiels.
1.3 Impact Effectif et réalité
Selon Amartya Sen, il ne suffit pas de connaitre les dotations d’un individu (les choix qui s’offrent à lui). C’est pourtant à ce stade que trop souvent les théories de RSE sociale s’arrêtent. Il convient de prendre en compte les fonctions d’utilisations qui amène ces dotations à se réaliser. Seulement alors nous évaluons sur les capabilités. En d’autres termes, il ne faut pas s’arrêter à évaluer des impacts potentiels, mais évaluer des impacts réels effectifs[3]. Le travail du Cirad (Macombe et al., 2013) identifie bien que ces impacts potentiels ne sont pas nécessairement effectif :
Le passage de variation d’effets potentiels à des variations d’effets réels de capacité dépend des conditions socio-économiques du contexte présidant à l’utilisation des capacités potentielles effectives mises à disposition. Ces contraintes font qu’il n’y a pas automaticité entre un effet potentiel effectif et un effet réel.
Nous avons alors besoin d’enrichir le modèle présent pour refléter cet écart entre potentiel et réel. Nous proposons alors un pondération de chacun des termes: pathway.value_n = pathway.value_n * pathway.realisation . Le facteur de pondération (nommé humblement facteur de réalisation) est à définir en prenant en compte le contexte méso et socio-économique du projet (grâce à une étude des tendances, des dépendances…). Il est d’ailleurs intéressant d’identifier le facteur de réalisation car le comparatif des impacts potentiels et effectifs donne des informations utiles à la compréhension des leviers d’actions possibles. C’est pourquoi nous feront en sorte de pouvoir récupérer ce facteur de réalisation afin de l’étudier.
Prenons néanmoins en compte la difficulté d’établir systématiquement un tel facteur. Bien souvent, les relations utilisées par les pathways de type 1 dépendent déjà du contexte (elles reflètent en tout cas celui de l’étude dans laquelle elles ont été réalisées). Cela signifie que les résultats de ces pathways comprennent déjà le facteur de réalisation, et qu’il convient alors d’estimer l’impact hors du contexte. Cela n’est pas systématiquement évident, mais possible s’il y a une bonne compréhension de la partie impactée et une étude des tendances et des dépendances. Quant aux pathways de type 2, l’estimation de l’impact effective.
2/ Qu’est ce qu’un Pathway ?
2.1 Définition
Nous avons clarifié quelques éléments d’ordre philosophique sur les choix éthiques de l’application. Il nous semble important de clarifier ce qui est d’ordre méthodologique et syntaxique.
Les relations reliant les variables du cycle de vie aux Endpoints sont appelés Pathways, chemins. Cependant il n’existe aucune théorie communément accepté sur la mesure d’impact sociaux et la nature de ces pathways, il convient alors de choisir une théorie existante. Cela demande de faire preuve de transparence sur comment son travail utilise ou modifie cette théorie pour l’adapter à ses besoins, ainsi que sur la manière de vérifier les hypothèses nécessaires à la bonne utilisation de la théorie et de l’éthique porté par le projet.
Clarifions d’abord ce que nous entendons par pathways. Au sens de Macombe et al. [4], nous retiendrons la définition suivante :
Un pathway est une relation (ou un ensemble de relation) entre une variable dont la valeur est assez facile à obtenir et un effet/impact social résultant de cette valeur, accompagné de ses conditions d’usages.
Cette définition résume les propos tenus et rajoute une caractéristique: les conditions d’usages. On comprend que les impacts potentiels ne soient pas tous évaluables de la même manière, en qu’en plus, selon le degré de maturité de la recherche scientifique sur un impact, on ne peut pas utiliser un certain type de pathways. Par exemple si l’on manque de données quantifiables ou de preuves sur une relation empirique. Dans notre travail, il convient alors de bien comprendre le niveau de maturité d’un impact afin d’utiliser une méthode adaptée pour l’évaluer. Avant de plonger dans la méthodologie de l’outil, voyons quelques exemples de pathways présentés par Macombe et al.
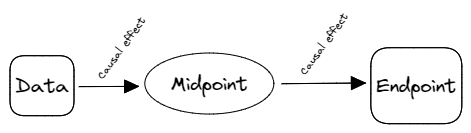
Image 2: Caractérisation causale des impacts
Le schéma ci-dessus met ainsi en exergue que ces relations causales peuvent demander plusieurs étapes. En anglais, les Midpoints représentent le résultat d’une variable après une étape causale (par exemple toutes les étapes intermédiaires qui suivent à l’annonce du médecin : « vous avez un cancer » ). Quant aux Endpoints, ce sont les résultats en fin de chaîne causale (ici donc la guérison ou la mort). Ces Endpoints sont attribués à des valeurs du modèles de valeur comme expliqué plus en détail dans la Partie pondération
2.2 Quelques exemples de pathways
2.2.A Pathway A: Calculer les emplois créés/détruits
Ce premier pathway appartient à la famille des pathways des relations simples et intuitives. Elle repose sur un calcul de différence entre les scénarios d’avant et d’après le changement. Il s’agit presque toujours de prévoir des effets et non des impacts sociaux.
2.2.B Pathway B: La richesse créée par un cycle de vie influence la santé d’une population pauvre
Ce second pathway appartient à une famille de pathway où l’on repère une corrélation forte entre un impact social et une variable Z (exemple: l’espérance de vie semble corrélé aux revenus moyens). De cette corrélation, il est possible d’extrapoler une relation statistique. Il convient de bien déterminer son domaine de validité (ici les Macombe et al. ont déterminés le domaine valable tant que: revenus/tête/an < 10 000$). Nous disposons alors d’une formule mathématique reliant les deux côtés, valable si certaines conditions sont rencontrées. On devra bien sûr y ajouter des facteurs d’atténuation qui représente la réalisation de cet impact potentiel (valable si la richesse est bien redistribuée à la population dans ce cas l’espérance de vie augmente, si ce sont des riches qui s’accaparent la richesse, raté, il faut calculer la richesse effective).
2.2.C Pathway C: La matrice des risques liés au stress au travail
Ce troisième pathway appartient a une troisième famille, plus complexe car multi-variable. Le stress au travail (Karacek, 1990 et Siegrist 1996) est généré par une multitude de variable, et génère de multiples formes d’affectations, on ne peut établir un pathway unique, d’autant plus qu’il faut tenir compte du fréquent cumul de ces conditions de stress. Il faut une matrice. Dans chaque case, on indique en odd-ratio[5] les résultats qualitatifs et quantitatifs ainsi que les conditions d’usages de la rencontre d’une variable de stress et d’une forme d’affectation.
3/ Application Donut: Méthodologie d’évaluation des pathways
3.1 Méthodologie
Cette partie détail le code et la méthodologie liée à l’évaluation des pathways. Prenons le temps d’expliquer comment s’est construit ce modèle. Nos recherches et les réflexions restituées en première partie nous on amené à considérer plusieurs nature de pathways, et plusieurs manière d’évaluer chacun des pathways, selon leur différentes natures. Nous avons décidé de proposer un code assez souple afin de ne pas le rendre obsolète dans le futur. Ainsi nous invitons chacun à s’approprier la manière dont sont créer les pathways afin d’y renseigner leurs relations empiriques ou statistiques. Cette souplesse se traduit dans l’acceptation de la complexité de l’évaluation des pathways « non quantifiables », et dans l’acceptation du manque de maturité des connaissances scientifiques sur certaines relations, et où l’évaluation tiens plus du nez que d’un théorème.
Nous distinguons ainsi deux types de pathways, que nous détaillerons dans les parties 3.4 et 3.5):
Les pathways de type Calcul: ceux que l’on peut modéliser avec des outils mathématiques. Cette catégorie considère des relations simples, des relations statistiques, des matrices d’odd-ratio… On peut y retrouver des pathways des 3 familles de Macombe et al. si la relation est assez mature.
Les pathways de type Estimate: ceux que l’on évalue par comparaison subjective avec la référence. Ce sont les pathways qui ne sont pas encore assez mature ou ceux avec lesquelles la quantification n’est pas possible.
La mécanique est alors la suivante:
D’abord on importe la base de données des pathways, on stocke leurs caractéristiques dans une classe.
Ensuite, pour chaque pathway importé, on récupère les données d’entrées et on applique la méthode associée à son type (calcul ou Estimate).
Enfin on stocke la valeur de sortie dans la classe du pathway en question.

Image 3: Méthode de l'évaluation des pathways
3.2 Articulation avec la base de donnée
Pour importer la base de données, nous utilisons la function read_excel() de la librairie python Pandas. Nous stockons la base de données pathways_data.
> main.py
pathways_data = pd.read_excel(name_file, '4.Pathways_recap')
Puis nous appelons la fonction get_pathways_list() afin de s’occuper de chaque chemin indépendamment:
Création d’un objet CreatePathway qui caractérise le chemin que l’on regarde.
Récupération des informations de la base de données pathways_data avec
get_info().Récupération de la précision avec
get_precision().En fonction du type du pathway, appel de la fonction
estimate()oucalcul()pour déterminer la valeur de l’impact potentiel de ce chemins, dont le fonctionnement est détaillé en partie 2.4 et 2.5.
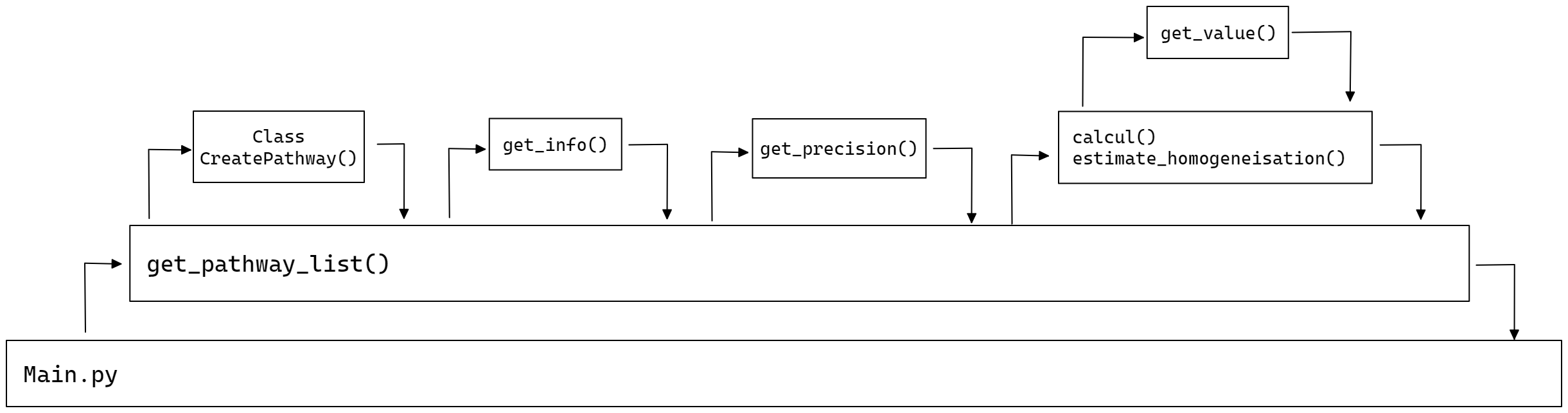
Image 4: Structure d'appel des fonctions pour l'évaluation des pathways
Toutes ces données sont extraites de la base de données panda pour être stockées dans les attributs de la Classe CreatePathway.
Voici par exemple le code de la fonction get_info(), ou l’on vient récupérer les paramètres stakeholder, type, entry et name.
> Pathways.py
def get_info(self, pathways_data):
# Get output info
self.stakeholder = str(pathways_data.loc[pathways_data['Pathway_ID'] == self.ID, 'Output_stakeholder'].iloc[0])
type_ = str(pathways_data.loc[pathways_data['Pathway_ID'] == self.ID, 'Type'].iloc[0])
type_ = type_.replace(' ', '').replace('[', '').replace(']', '').split(';')
self.type = int(type_[0])
if type == 2:
self.statistique_model = str(type_[1])
# Get input info
id_ = str(pathways_data.loc[pathways_data['Pathway_ID'] == self.ID, 'Entry_ID'].iloc[0])
id_ = id_.replace(' ', '').replace('[', '').replace(']', '').split(';')
name_ = str(pathways_data.loc[pathways_data['Pathway_ID'] == self.ID, 'Entry_Name'].iloc[0])
name_ = name_.replace(' ', '').replace('[', '').replace(']', '').split(';')
self.entry = id_
self.name = name_
3.3 La Classe CreatePathway
L’utilisation d’une classe pour les pathways a pour avantage de regrouper toutes leurs informations et méthodes au sein d’une même structure. Il en ressort un code plus léger et compréhensible.
Lors de l’appel de la fonction get_pathway_list(), on créer un objet CreatePathway() pour chaque chemin qui est activé (la base de donnée des pathways pouvant contenir des chemins qui ne sont pas utilisés dans le modèle de valeur choisit).
Ainsi le but de la fonction get_pathway_list() est de renvoyer dans main.py une liste python contenant tous les objets CreatePathway qui représente chacun des chemins utilisés pour calculer les effets d’impact potentiel.
Les chemins stockés dans cette liste comprennent dans leurs attributs toutes les données nécessaires à leur normalisation, pondération et analyse graphique. L’attribut self.value possède déjà une valeur correct puisque les fonctions calcul() ou estimate_homogeneisation() ont été appelés dans get_pathway_list().
Voici la liste des attributs que possède chaque pathways:
ID,entry, type, statistique_model ,realisation sont des attributs utilisés comme paramètres d’entré du pathways.
value, value_n sont les attributs pour stocker la sortie brute et la sortie normalisée et pondérée.
name, stakeholder sont utilisées pour le graphique du Donut.
precision contient initialement les valeurs individuelles des précisions des entrées, puis on écrit dessus la valeur de l’erreur potentielle calculée à partir de ces précisions.
> Pathways.py
def __init__(self, id_):
self.precision = []
self.value = None
self.ID = id_
self.entry = {}
self.value_n = ''
self.name = []
self.type = 0
self.stakeholder = ''
self.statistique_model = 'linear'
self.realisation = 1
Les attributs de la classe et les méthodes de celle-ci sont détaillés ici.
3.4 Pathways de type calcul
Cette méthode concerne les chemins dont les études préalables permettent d’établir une relation causale assez admise, ou bien dont les données sont issues d’un autre outil, et il convient d’adapter la valeur au projet par des relations assez simplement modélisable avec des outils mathématiques. Cette catégorie considère donc des relations de calculs simples, des relations statistiques, des matrices d’odd-ratio…
Nous fixons alors l’attribut self.type à 1. Puis, nous demandons alors à l’algorithme d’appeler la méthode Class.pathway_calcul() pour évaluer le chemin. Cette méthode renvoie une valeur d’impact potentiel absolu et non interprétable, que l’on stocke dans self.value.
La nature des variables d’entrées de la relation du chemin est assez large, la fonction get_values() appelé permet d’importer des valeurs, des listes de valeurs ou bien des matrices de valeurs (sous forme de liste de liste: [[a ; b] ; [a ; b]] par exemple).
Cependant, la nature de la variable de sortie est imposée: une valeur positive non nulle.
Cette hypothèse est importante et à bien noté, les chemins doivent être définit pour avoir leur image sur ]0 ; +∞[. Par exemple, si l’on souhaite caractériser le taux potentiel de trajet en bus pour un projet qui est en zone sans service de bus, le chemin porterai sur le taux potentiel de trajets non réalisés en bus. La probabilité de voir ce taux nul est très faible, voir impossible. L’image du pathway est ainsi « probablement » redressé sur ]0 ; +∞[.
La méthode « calcul() »
La méthode de calcul de tous les chemins sont renseignés dans la fonction calcul(). Nous utilisons un dictionnaire nommé e afin de stocker les valeurs des entrées du chemin (pour rappel, les identifiants des variables d’entrée du chemin sont stockés dans self.entry grâce à get_info(), appelé plus tôt dans get_pathway_list()).
> Pathway.py
# Value attribution - généralisé
e = {}
for i in range(0, len(self.entry)):
e[self.name[i]] = get_values(LCI_table, self.entry[i])
if type(e[self.name[i]]) == str:
e[self.name[i]] = float(e[self.name[i]])
L’utilisation de ce dictionnaire permet une bien plus grande lisibilité du code puisque l’on appelle une variable d’entrée avec e[nom_de_la_variable]. Le résultat de la relation est écrit dans l’attribut self.value.
# Name: Land Change / ID:6
if self.ID == 6:
irreversible = (e['arable_urbanisation']-e['renaturalisation'])
forest = e['deforestation']*e['land_stress_factor']
self.value = (irreversible+forest)/100
Le choix d’utiliser un dictionnaire impose une deuxième hypothèse forte: ne pas changer le nom des variables d’entrées dans la base de données pathway_data. Cependant, ce choix présente surtout de nombreux avantages:
On s’affranchit d’une structure lourde on l’on doit stocker dans des variables locales chacune des entrées pour chacun des chemins: le dictionnaire s’adapte à la longueur de la liste des entrées.
On s’affranchit d’un problème d’ordre des valeurs, ou l’on doit connaitre précisément la position de chacune des variables dans la liste des entrées. Le choix est donc orienté vers la connaissance des noms et pas des positions. Pour l’être humain, ce choix permet une meilleure visualisation et compréhension.
La lisibilité de la fonction, afin de comprendre les relations qui sont implémentées.
En bref: *Ne pas changer le nom des variables d’entrées dans la base de données pathway_data. Les chemins doivent être définit pour avoir leur image sur ]0 ; +∞[. *
La normalisation
Le résultat de l’évaluation par calcul() est sous la forme de valeur d’impact potentiel. Pour exprimer l’appréciation ou la dépréciation de capabilité, il convient de calculer l’effet d’impact associé. L’effet d’impact est défini comme le différentiel, en terme d’impact, entre le point de départ et le point d’arrivée. En d’autres termes, si l’on imagine que l’on lance une balle de tennis, l’impact de départ peut être identifié comme le vecteur du mouvement de cette balle. Dans nos scénarios, on change les conditions dans lesquelles évolue la balle, cela perturbe sa trajectoire. Ainsi l’effet d’impact engendré est représenté par le vecteur de « perturbation » de la trajectoire de la balle.
Concrètement, pour notre méthodologie, nous modélisons cet effet d’impact par un rapport entre la valeur d’impact potentiel du scénario sur celle de la référence. On fera attention à bien comparer pour la même unité fonctionnelle. On obtient alors (en %) une valeur qui représente l’appréciation de la capabilité (si on est au-dessus de 100%) ou une dépréciation (si l’on tombe en dessous de 100%). L’hypothèse d’image sur ]0 ; +∞[ prend son sens ici puisque l’on divise des valeurs de cette intervalle: exclure le 0 est nécessaire.
> Assessment.py
> get_comparison()
if pathway.type == 1:
# Normalisation by the reference value for the pathway
pathway.value_n = pathway.value / pathway_list_scenario[nb_ref][n_pathway].value
# Transforming in a effective impact on capabilities
pathway.value_n = pathway.value_n * pathway.realisation
Nous stockons cette valeur dans l’attribut self.value_n de nos Class CreatePathway, nous n’écrasons pas la valeur de self.value pour deux raisons. Premièrement, cela garde une mémoire de la valeur brute, utile pour vérifier les ordres de grandeurs par exemple. Deuxièmement, cela évite tout problème de mise à jour de variable qui dépendent des valeurs brutes des pathways (par exemple, cela garde une mémoire des self.value brutes des références choisies, ainsi lors de normalisation successive, on applique bien l’opération sur les valeurs brutes et pas sur des valeurs déjà modifié par la précédente référence. )
3.5 Pathways de type estimate
Cette méthode concerne des pathways dont les relations causales sont admises mais dont le modèle relationnel est peu aboutit, voir n’existe pas. L’évaluation fait alors appel aux études de contexte, de tendance pour évaluer si l’impact du midpoint sera plus positif ou négatif par rapport à un scénario de référence (cette référence pourra être modifier par la suite, on peut alors considérer le scénario d’une évolution des tendances sans interventions comme référence initiale).
La démarche s’inspire directement de la méthode de Classement proposée par Catherine Macombe et al. [5] avec 3 niveaux d’amélioration de la capabilité et 3 niveaux de dégradation de la capabilité. La note attribuée est alors entrée dans l’inventaire du cycle de vie.

Tableau 1: Les niveaux d'impact d'un pathway
La subjectivité ayant une part forte dans le choix de notation, il convient d’effectuer ce choix de manière éclairée en ayant conscience des points suivants:
Le choix est orienté sur l’amélioration ou la dégradation potentiel d’une capabilité qui compose une valeur du modèle de valeur choisit. Autrement dit on estime subjectivement l’impact potentiel sur un Endpoint.
L’estimation de l’impact est absolu dans le sens ou on ne compare pas avec d’autres Enpoint ou d’autres valeurs, simplement avec l’impact du scénario de référence.
La complexité est de savoir ou l’on arrête de considérer les influences en cascade des variables d’entrées. Le choix peut être simplifier si une étude des tendances, un diagramme des boucles causales ou études similaires ont été réalisés.
Considérer les boucles de rétroactions et les déplacements d’impacts possibles.
On appelle la méthode Class.estimate_homogeneisation() pour estimer la valeur du niveau d’impact potentiel relatif, à référence fixée lors de la saisie de la donnée. La valeur est stockée dans self.value.
En bref: On note l’impact sur la capacité sur [D3, D2, D1, N, A1, A2, A3] Pour une étude, veillez à toujours comparer avec le même scénario de référence.
La méthode estimate_homogeneisation()
Cette méthode récupère la notation de chacune des entrées d’un chemin et fait une note moyenne. Nous considérons à cette étape que les pathways construits permettent une agrégation aussi simplifiée. Si cela n’est pas le cas, il convient de scinder en plusieurs pathways différents les entrées.
def estimate_homogeneisation(self, LCI_table):
summ = 0
# Aggregation for pathway
for i in range(0, len(self.entry)):
e = str(get_values(LCI_table, self.entry[i]))
e = e.replace('A', '').replace('D', '-').replace('N', '0')
e = int(e)
self.entry[i] = e
summ += e
self.value = summ / len(self.entry)
Modèles statistiques
Pour normaliser, afin d’obtenir un résultat de dépréciation et d’appréciation des capabilités en % de la référence, il y a besoin d’un arbitrage sur l’étendue potentiel des valeurs que peuvent prendre les impacts potentiels pour un pathway de type estimate. Autrement dit, un A3 pour le scénario et A2 pour la référence, ça correspond à 120% ? 150% ? 2000% ? Pour modéliser cela, nous décidons de caractériser l’effet d’impact en répartissant l’impact selon un modèle statistique.
Le choix de ce modèle statistique est conditionné par l’importance de l’impact déterminé, par l’étude du contexte, des risques et tendances du projet ainsi que le facteur de réalisation. Les objectifs de ce modèle sont multiples:
Limiter les erreurs de subjectivité.
Prendre en compte une sensibilité d’évolution de la capabilité, qui dépend du contexte et des tendances.
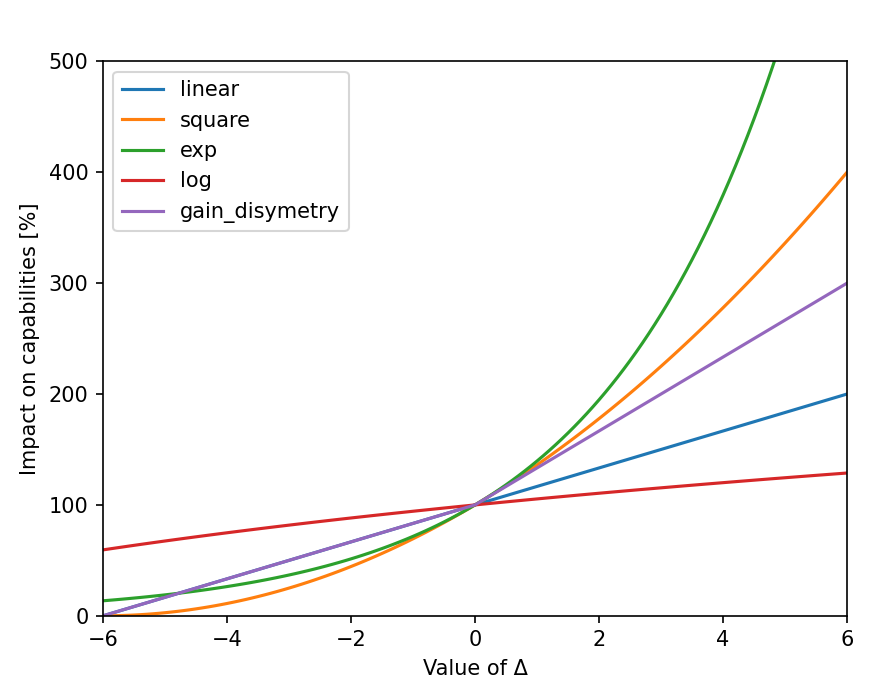
Pour l’instant, l’outil Donut comprend 5 modèles de répartitions statistiques:
linear: $f(Δ)=1 + Δ/6$
square: $f(Δ) = 1 + 2*(Δ/6) + (Δ/6)²$
exponential: $f(Δ) = exp(Δ/3)$
logarithmic: $f(Δ) = 1 + ln(1+Δ/18)$
gain_disymetry:
si $Δ<0$: $f(Δ)=1 + Δ/6$
si $Δ>0$: $f(Δ)=1 + Δ*2/6$
Vous retrouverez ces expressions en cherchant des fonctions de type ($a+bx$, $a+bx+cx²$, $a*exp(bx)$, $1 + ln(1+cx)$) qui vérifient les hypothèses:
$f(0) = 1$
L’image de [-6,6] par l’opérateur Z est [0, Z(2)]. Par exemple, pour l’opérateur carré, on chercher le polynôme tel que f(6)=2². Autrement dit, pour les modèles linear, square, exponential, logarithmic, les images sont respectivement [0, 2], [0, 2²], [ε, exp(2)], [ε, ln(2)]
Si jamais l’algorithme ne détecte aucun modèle connu pour un chemin, il appliquera par défaut un modèle statistique linéaire arbitraire (A3 = 100% d’appréciation, D3 = -100% d’appréciation), en appliquant la théorie de dissymétrie du gain (théorie qui montre que les impacts négatifs ont un effet deux fois plus puissant que les impacts positif).
La méthode estimate_statistical()
Comme ce modèle statistique utilise les valeurs d’appréciation et dépréciation à la fois du scénario et de la référence, nous considérons que ce module fait partie de l’étape de normalisation. Cette méthode est ainsi appelé dans get_comparison(), en même temps de l’étape de normalisation des pathways de type calcul:
> Assessment.py
> get_comparison()
# Type 2 pathway statistical method to normalize them
if pathway.type == 2:
pathway.estimate_statistical(pathway_list_scenario[nb_ref][n_pathway])
La méthode estimate_statistical() demande la un objet CreatePathway en paramètre. Ensuite, en fonction du modèle exprimé dans la base de données pathway_data, la valeur normalisé est calculée.
> Pathway.py
def estimate_statistical(self, ref):
Delta = ref.value * ref.realisation - self.value * self.realisation
if self.statistique_model == 'linear':
self.value_n = 1 + Delta / 6
elif self.statistique_model == 'square':
a, b, c = 1/36, 1/3, 1
self.value_n = a * Delta**2 + b * Delta + c
elif self.statistique_model == 'exponential':
self.value_n = exp(Delta/3)
elif self.statistique_model == 'logarithmic':
self.value_n = 1 + log(1 + Delta/(6*exp(1)))
else:
# Using linear model with gain dissymetry theory
if self.value >= ref.value:
self.value_n = 1 + Delta*2 / 6
if self.value < ref.value:
self.value_n = (1 + Delta / 6)