5/ LCI
Résumé
Le Life Cycle Inventory (LCI) consiste en la collecte des variables d’entrées de tous les pathways activés. La collecte s’attarde sur:
Les données de localisation, de temporalité et de contexte, aux différentes échelles du projet.
Le niveau de précision de ces données, selon 4 dimensions (temporelle, géographique, résilience, précision). Une fois ces informations collectées, elles sont consignées dans les bases de données de type LCI du tableur du projet.
1/ LCI - Life cycle Inventory
1.1 Souplesse de la structure LCI
L” inventaire du cycle de vie (appelé LCI, de l’anglais Life cycle Inventory) correspond à l’ensemble des données qui caractérisent les multiples capitaux d’un projet. Autrement dit, le LCI est l’inventaire des données de toutes les variables d’entrées de tous les chemins qui définissent tous les Endpoints du modèle de valeur. Autrement dit, c’est une sacrée base de données C’est pour cela que l’outil l’aborde sous de nombreux aspect.
La structure est conçu pour classifier l’information en 5 capitaux différents[1] :
Capital Economique
Capital Humain
Capital Naturel
Capital Social
Capital Institutionnel
Chaque capital est ensuite divisé en sous capitaux, ils peuvent être multiples. Par exemple, un sous-capital important du capital économique est le sous-capital technique. Cette approche par capitaux multiples à l’avantage d’être complète sur la nature des informations à récupérer. Elle exprime aussi l’effort méthodologique de sortir du seul indicateur financier : cette proposition par les capitaux multiples vient redéfinir la valeur.
Il est aussi possible de classifier selon la catégorie de partie prenante impactée. Voir la partie sur le périmètre d’impact.
Cette souplesse permet d’afficher ou de cacher les variables que l’on souhaite selon le point de vue que l’on veut adopter. Cela permet une meilleure navigation dans la base de données et assure une certaine étendue.
1.2 Point de vue sur les dimensions de l’information et des impacts
Le point de vue tri-dimensionnel contexte-temporel-localisation expliqué pour la nature des informations est à garder en tête:
Informations de localisation (climat, agriculture, sols, ressources naturelles…)
Informations temporelles (efforts de planification déjà prévu, données historiques utilisables, rapports annuels, politiques gouvernementales…)
Informations contextuelles (complexité du système, parties prenantes, nature structures, situation géopolitique..)
Cette tridimensionnalité s’exprime aussi pour la nature des impacts :
Temporel: court, moyen et long terme.
contexte: niveau d’impact direct, indirect, système.
Localisation: taxonomie des environnements emboités:
Ontosystème (caractéristiques, états, compétences… propre à un individu).
Microsystème (milieu immédiat de l’individu).
Mésosystème (réseau de connexions entre les microsystèmes).
Exosystème (paramètre de l’env. qui influe de manière indirecte, ex le contexte de travail des parents).
Macrosystème (contexte culturel plus large qui influence l’ensemble des systèmes).
Chronosystème (réfère aux transitions écologiques qui se vivent).
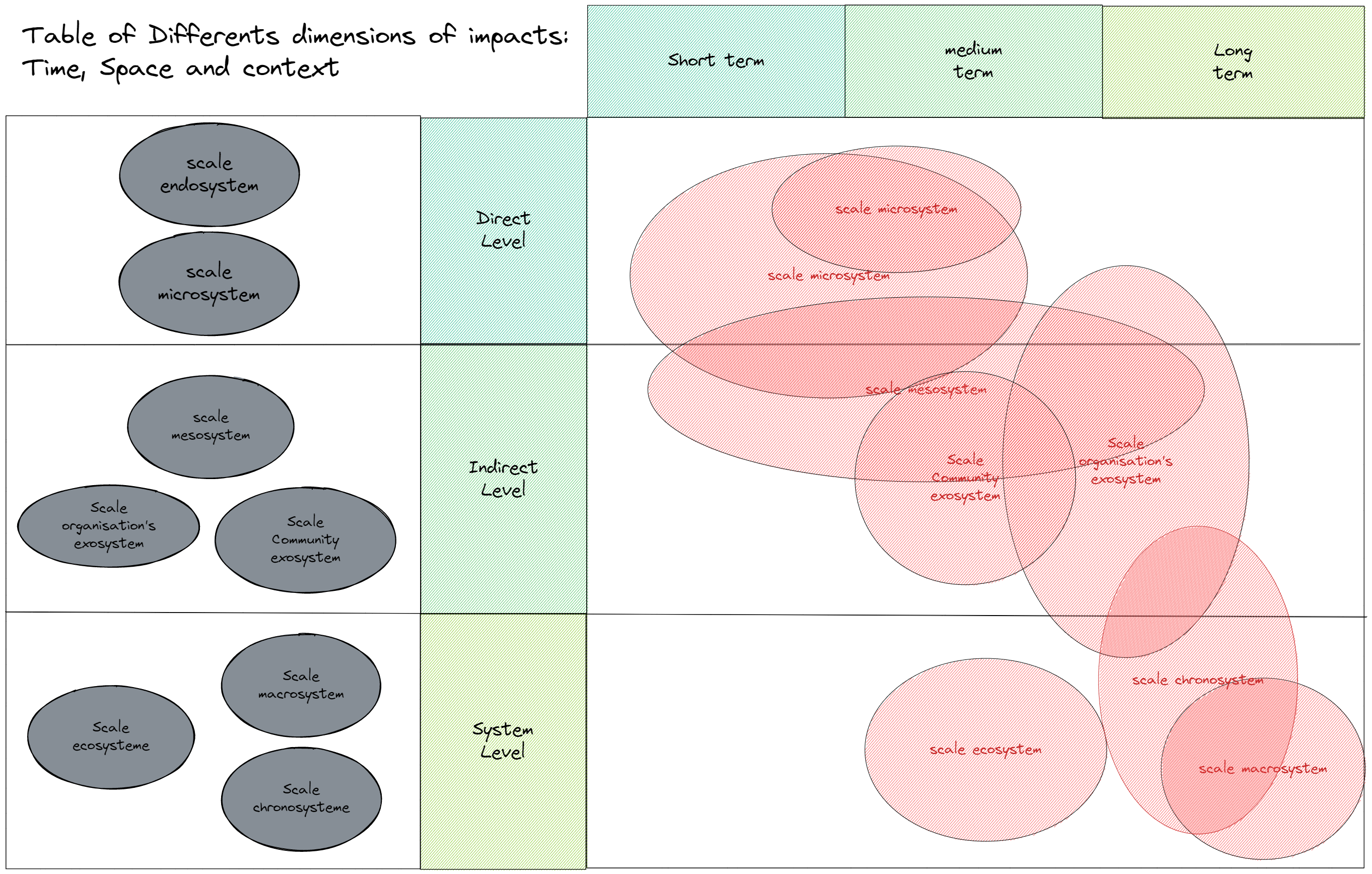
Image 1: Table des différentes des impacts: temps, espace et contexte
La précision de l’information relevée lors d’analyses et de récoltes sur le terrain peut être enrichit par un regard croisé sur ce modèle multi-dimensions inspiré de SiD (Symbiosis in Developpment)[2] . Le graphique précédent illustre les relations entre ces dimensions, et peut servir de support pour réfléchir l’information par le prisme de ces dimensions.
2/ Collecte des données
On distingue deux type d’informations en théorie systémique :
Information structurante : incluse dans les mémoires du système (ex ADN dans cellule).
Information circulante : présente au sein des échanges entre et au sein des systèmes. Dans les démarches de collecte, prévoir la récolte de ces deux types d’informations.
Pour satisfaire les axiomes de subjectivité et diversité, il y a besoin de multiplicité des méthodes (conforter des résultats, diversifier les regards, déterminer le seuil de saturation théorique.). Il convient alors de croiser les résultats avec une méthode de triangulation jugée pertinente.
Plusieurs méthodes de collecte d’information sont à mener sur site:
Observer les faits (selon le cadre POEMS - Personnes Object Environnement Message Services), relever ainsi ce que le déclaratif ne permet pas d’exprimer: comportements routiniers, reflexes ou intériorisés. On consigne tout.
Interview (méthode QQOQCC) pour collecter le contexte, la culture, les activités, messages; temporalités, social. Il faut avoir une posture d’écoute active et faire preuve de neutralité et d’intérêt.
Questionnaires ou sondage si interview pas possible.
Récolte sur des documents internes au projet (PLU, programme, études techniques spécifiques, résultats d’ateliers antérieurs).
Récolte des données issues des ateliers de compréhension du système et des périmètres.
Récolte sur des base de données libres et consultables[3] :
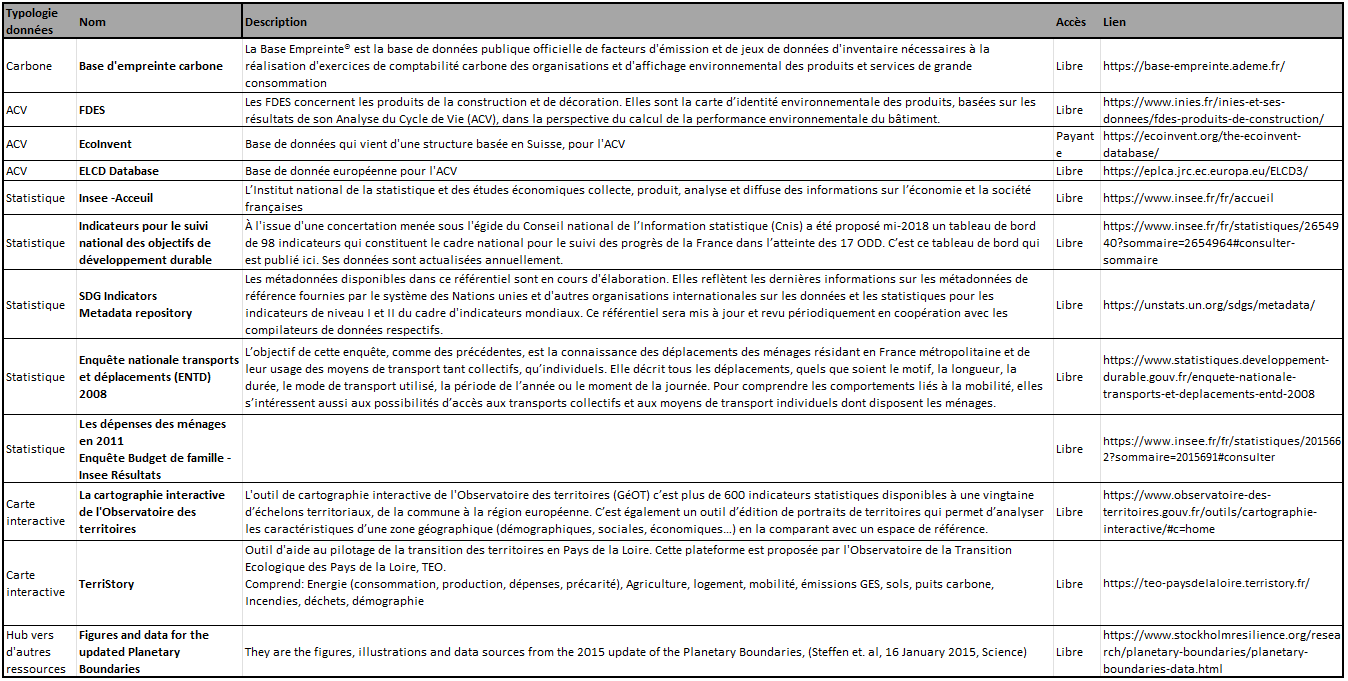
Tableau 1: Extrait de la base de données des bases de données libre et consultables.
Récolte de données sur d’anciens projets.
3/ Structure des bases de données
Dans cette partie est expliqué comment l’information relevé est stocké afin d’être utilisé pour l’application Donut. On distingue trois bases de données qui servent à l’outil. Les deux premières sont collaboratives : elles ne dépendent pas du projet et constituent un répertoire qui ne fera que s’enrichir avec le temps. La dernière est un modèle propre à chaque projet, à répliquer pour chaque scénario:
Base de données des pathways : pathway_data
Base de données des Endpoints : database_endpoint_impact
Base de données LCI
3.1 Base de données des pathways
Cette base de données se nomme « pathway_data ».
Son rôle est de transmettre les informations des différents chemins. La base de données contient toutes leurs caractéristiques, à l’exception de la règle de calcul. Ces caractéristiques seront alors lues et importées par l’algorithme, puis stocké dans des objets de type classe CreatePathway.
Cette base de données n’est pas propre au projet : elle est générale et collaborative. Ainsi, elle est vouée à être mise à jour et enrichie avec le temps. L’utilisateur peut se l’approprier s’il souhaite apporter une contribution à l’outil. Sinon il peut simplement l’utiliser telle quelle en suivant le guide d’utilisation.
WARNING:
a/ Veillez à ne pas modifier les en-têtes des colonnes : le code se sert de ceux-ci pour récupérer les données.
b/ Dans les listes, utiliser « , » ou « ; » pour séparer deux informations. Pour un nombre à virgule, il faut par contre l’écrire avec « . » comme séparateur. Par exemple « 3.5 ». **
Voici la forme que prend la base de données, séparer en deux parties uniquement dans un soucis de lisibilité ici :
Pathway_ID |
Name |
Type |
Description |
Entry_Name |
Entry_ID |
Entry_unity |
… |
|---|---|---|---|---|---|---|---|
1 |
Pathway_1 |
1 |
Afin d’évaluer pathway_1… |
[nom1; nom5; nom54] |
[HH1; HH5; HG4] |
[kgCO2eq; %; Na] |
… |
2 |
Pathway_2 |
2, gaussian |
Afin d’évaluer pathway_2, il faut… |
[nom2, nom3; nom4] |
[EC2; IS3, IS4] |
[Na; Na; Na] |
… |
… |
… |
… |
… |
… |
… |
… |
Tableau 2: pathway_data, colonnes A-G
Les colonnes A à D présentent des informations générales sur le chemin :
Pathway_ID: C’est l’identifiant avec lequel le code reconnait les chemins. Cet attribut est stocké dans self.ID. Il sert notamment à appeler les bons pathways pendant l’étape d’agrégation
Name: C’est l’attribut qui sert à désigner l’outil, il est simplement visuel pour faciliter le remplissage des bases de données
Type: Le type du chemin indique si la méthode d’évaluation qui lui est attribuée est
calcul()ouestimate(). Un type 1 correspond à la méthodecalcul(). Un type 2 correspond à la méthodeestimate(). Dans le cas d’un type 2, il convient de rajouter dans la case Type la nature du modèle statistique attribué. Tous les modèles disponibles sont actuellement : linear, square, gaussian. Ils sont présents dans la feuille d’introduction des bases de données.Description: Présente une courte description du chemin, avec des conseils ou indications à suivre afin de récupérer une donnée la plus précise possible.*
Les colonnes E à G présentent les paramètres d’entrées du chemin :
Entry_Name: Contient un string, une liste de string [a,b], ou une matrice de string [[a, b], [c, d]] en fonction des besoins. L’information contenu est le nom de chaque entrée utilisé par le chemin. Il est IMPORTANT de ne pas les modifier. Ces noms doivent rester identiques à ceux rentrés dans le module de calcul du chemin (qui est stocké dans la méthode calcul() de l’objet CreatePathway associé au chemin.). Dans sa version alpha, l’outil ne propose pas de vérificateur des noms, c’est donc manuellement qu’il faudra corriger chacune des erreurs qu’une mauvaise manipulation de l’outil peut causer. Ces noms sont stockés dans l’attribut self.name de l’object CreatPathway associé au chemin.
Entry_ID: Contient un string, une liste de string [a,b], ou une matrice de string [[a, b], [c, d]] en fonction des besoins. Entry_ID a la même structure que Entry_Name, puisqu’il contient les identifiants des entrées nommées dans Entre_Name. Ces identifiants sont stockés dans self.entry de l’object CreatPathway associé au chemin.
Entry_unity: Contient un string, une liste de string [a,b], ou une matrice de string [[a, b], [c, d]] en fonction des besoins. Cette information n’est pas relevée par le code, mais elle sert à vérifier la cohérence des données relevées avec l’unité qui est attendue
… |
Entry_unity |
Output_name |
Output_Stakeholder |
Output_unity |
Activate |
|---|---|---|---|---|---|
… |
[Na; kgCo2eq; %] |
midpoint_1 |
Users |
% |
1 |
… |
[Na;Na;Na] |
midpoint_2 |
Society |
% |
0 |
… |
… |
… |
… |
… |
… |
Tableau 3: pathway_data, colonnes G-K
Les colonnes H à J présentent les informations de la sortie du chemin :Output_name: Présente le nom de ce que l’on évalue en sortie, à valeur indicative.
Output_Stakeholder: Présente le nom de la partie prenante impacté par le phénomène que modèlise ce chemin. Cette information est lut puis stocké dans l’attribut self.stakeholder de l’objet CreatePathway associé au chemin.
Output_unity: Présente l’unité de ce que l’on évalue en sortie, afin de permettre une vérification de la cohérence des modules de calcul par les modérateurs.
La colonne K présente le statut du chemin :
Activate: Représente le statut du chemin. 0 si le chemin n’est pas utilisé. 1 si le chemin est utilisé.
3.2 Base de données des Endpoints.
Cette base de données se nomme « database_endpoint_impact ».
Son rôle est de transmettre les informations des différents Endpoints. La base de données contient toutes leurs caractéristiques. La base de donnée est importé en panda.DataFrame dans la variable database_endpoint_impact.
Cette base de données reflète directement le modèle de valeur implémenté dans l’outil. Il convient alors de modifier cette base de données et de l’ajuster à l’éthique du projet.
Cette base de données n’est pas propre au projet : elle est générale et collaborative. Ainsi, elle est vouée à être mise à jour et enrichie avec le temps. L’utilisateur peut se l’approprier s’il souhaite apporter une contribution à l’outil. Sinon il peut simplement l’utiliser telle quelle en suivant le guide d’utilisation.
Voici la structure de cette base de données :
Stakeholders |
Name |
Category_ID |
Pathways |
Objective |
Weights |
|---|---|---|---|---|---|
Society |
Endpoint_1 |
OUT |
[1; 2; 3; 4; 5; 6; 7] |
0.8 |
[0.1; 0.2; 0.1; 0.2; 0.1; 0.15; 0.15] |
Chain_value_actor |
Endpoint_2 |
IN |
[7; 9; 13] |
[0.6; 0.1; 0.3] |
|
… |
… |
… |
… |
… |
Tableau 4: database_endpoint_impact, colonnes A-E
Stakeholders: Contient un string issu de la liste des parties prenantes impactées (Local_Community, Society, Consumers, Workers, Chain_Value_Actors). Cette information est utilisée pour savoir où tracer l’Endpoint. Selon la valeur de l’attribut self.stakeholder de l’objet de classe Parameters(), l’Endpoint peut ne pas être affiché.
Name: Présente le nom de l’Endpoint évalué. C’est le nom qui figurera en label sur le Donut
Category_ID: Cette informations peut prendre deux valeurs : - IN si l’Endpoint est à représenter à l’intérieur du Donut. - OUT si l’Endpoint est à représenter à l’extérieur du Donut.
Pathways: *Contient un nombre ou une liste de nombre. Ce sont les identifiants des pathways associés à un Endpoint dans le modèle de valeur. Ces informations sont stockées dans la liste « pathways_id », variable locale de la fonction get_comparison() de Assessement.py *
Objective: Cette information permet de forcer la comparaison des sorties d’un chemin. Au lieu de comparer avec la valeur d’un scénario de référence, on compare avec la valeur entrée ici. Cela permet de forcer la comparaison avec les résultats souhaités d’une politique locale ou régionale, ou d’un objectif du programme.
Weights: *Contient un nombre ou une liste de nombre. Si le nombre est seul, il est égal à 1. Si c’est une liste de nombre, la somme fait 1. Ce sont les poids associés à chaque chemin dans la priorisation définit dans le modèle de valeur. Ces informations sont stockées dans la liste « weight », variable locale de la fonction get_comparison() de Assessement.py. Ces informations servent à agréger plusieurs valeurs de sorties dans un Endpoint qui décrit une des aires de protection (AoP). *
3.3 LCI
Dans cette partie, nous détaillerons la structure des bases de données d’inventaire du cycle de vie (LCI). Ces bases de données sont des copies du TEMPLATE présent dans les tableurs associés aux bases de données. Elles sont autant nombreuses que les scénarios : chaque scénario doit posséder sa base de données LCI. Dans le tableur, une base de données LCI est caractérisé par le nom de sa page : le préfixe SCENARIO indique à l’algorithme qu’il s’agit d’une base de données LCI d’un scénario La base de données du scénario A, par exemple, se nommera « SCENARIO - A ».
L’usage de cette base de données est détaillé dans le Guide utilisateur et la note aux contributeurs.
**WARNING:
Il convient de bien vérifier que les LCI sont bien nommés avec le préfixe SCENARIO.**
Voici la structure de la base de données, séparer en deux parties pour plus de lisibilité :
Capital |
Sub-capital |
ID |
Name |
Unity |
Description |
Group |
… |
|---|---|---|---|---|---|---|---|
Human |
Health |
HH2 |
name_1 |
% |
Describe name_1 % in population of specific stakeholder |
Local_community |
… |
Institutionnal |
Social tendencies |
IS1 |
D-N-A |
Evaluate name_2 impact |
Loal_community |
… |
|
… |
… |
… |
… |
… |
… |
… |
… |
Tableau 5: LCI, colonnes A-G
Les colonnes A à G présentent des informations indicatives sur les variables, ainsi que les informations de lien avec les autres bases de données (pathway_data) :
Capital: A titre indicatif. Pour aider à naviguer dans le LCI, donne le type de capital de l’information. Les type de capitaux sont hérités de la théorie des capitaux multiples porposés par Macombe et al. (Economique, Humain, Social, Naturel, Institutionnel)
Sub-capital: A titre indicatif. Pour aider à naviguer dans le LCI, donne le sous-type de capital de l’information. La liste des sous-types de capitaux est indiquée dans la page d’introduction des tableurs associés au base de données.
ID: C’est l’identifiant de la variable que l’on relève. L’identifiant est usuellement composé du la première lettre du capital, de la première lettre du sous-capital, et d’un numéro unique. Cette identifiant est utilisé dans la base de données pathway_data pour indiquer quel chemin utilise cette variable. Veillez à ne pas modifier le nom de l’identifiant.
Name: A titre indicatif. Permet d’identifier la variable lorsque l’on remplit la base de données. Permet aussi de vérifier l’identifiant indiiqué et celui présent dans la base de données pathway_data.
Unity: A titre indicatif. Permet de vérifier la cohérence de la variable relevé et de l’unité attendue.
Description: A titre indicatif. Permet de donner des conseils, des précisions sur la variable en question.
Stakeholder: *A titre indicatif. Aide pour la navigation dans la base de données. Permet de vérifier *
… |
Value |
Reliability of the source (/5) |
Temporal precision (/5) |
Spatial precision (/5) |
Technical performance (/5) |
|---|---|---|---|---|---|
… |
40 |
4 |
5 |
4 |
4 |
… |
A1 |
5 |
5 |
5 |
4 |
… |
… |
… |
… |
… |
… |
Tableau 6: LCI, colonnes H-L
La colonne H contient la valeur des variable s:
Value: Contient la valeur de la variable. Cette valeur est soit un nombre (si la variable est quantifiable), soit une notation d’appréciation comparée entre scénario et référence. Dans ce deuxième cas de figure, il est possible de renseigner la notation comme expliqué dans la méthode d’évaluation estimate(): la valeur appartient à [D3; D2; D1; N; A1; A2; A3]. Les D pour dépréciation, le N pour neutre et les A pour Appréciation.
Les colonnes I à L contiennent les précisions des variables :
Reliability of the source (/5): Notation entre 0 et 5. Voir gestion de la précision pour plus de détails.
Temporal precision (/5): Notation entre 0 et 5. Voir gestion de la précision pour plus de détails.
Spatial precision (/5): Notation entre 0 et 5. Voir gestion de la précision pour plus de détails.
Technical performance (/5): Notation entre 0 et 5. Voir gestion de la précision pour plus de détails.
4/ Gestion de la qualité des données
4.1 Gestion des risques
Parlons d’abord des risques.
La vocation de l’outil est de projeter des impacts en situation de routine, c’est à dire que l’on ne prendra pas en compte des évènements climatiques exceptionnels en tant que tel. Cela étant dit, l’évolution rapide des écosystèmes et du climat nous oblige à les considérer dans l’étude des tendances ou du contexte.
L’outil, dans sa méthodologie de calcul alpha ne modélise pas les risques climatiques. Il convient :
De les prendre en compte grâce à une étude des tendances ou du contexte.
Lors de la création d’un pathway, représenter ces risques dans le modèle de calcul si cela est jugé nécessaire.
4.2 Gestion de la précision
4.2.1 Dimensions des précisions
Concernant la précision, cette information accompagne chaque variable jusqu’au Donut. C’est une donnée très importante puisque l’on traite d’informations qui ne sont pas quantifiables, et par conséquent bien plus difficile à évaluer.
La précision de l’information est décomposée en 4 dimensions :
Fiabilité de la source: c’est le niveau de crédence que l’on peut accorder au résultat obtenu en fonction de la nature de sa source.
Précision temporelle: c’est la cohérence temporelle de l’information au regard de l’étude. Plus l’information est ancienne, plus il y de risque qu’elle ne soit plus d’actualité.
Précision géographique: c’est la précision qui caractérise si l’information représente bien les bonnes parties prenantes impactées.
Résilience technique: cette dernière est plus délicat, il s’agit de la présumée résilience dans le temps de l’information. La période de véracité de l’information peut être très restreinte, ou bien au contraire s’étendre sur plusieurs centenaires.
Pour chacune de ces dimensions, pendant la phase de collecte des informations, il conviendra de noter sur 5 chacune des dimensions, le plus objectivement bien sûr. Le tableau suivant donne une caractéristique pour chaque palier :

Tableau 7: Notation de la précision
La notation est alors à entrer dans chaque feuille de scenario, pour chaque variable, dans les colonnes suivants Value. Rentrer les précisions de l’information est nécessaire pour que la feuille soit « prête ».

Image 2: Feuille de scénario, avec datasheet ready en vert
4.2.2 Calcul de précision
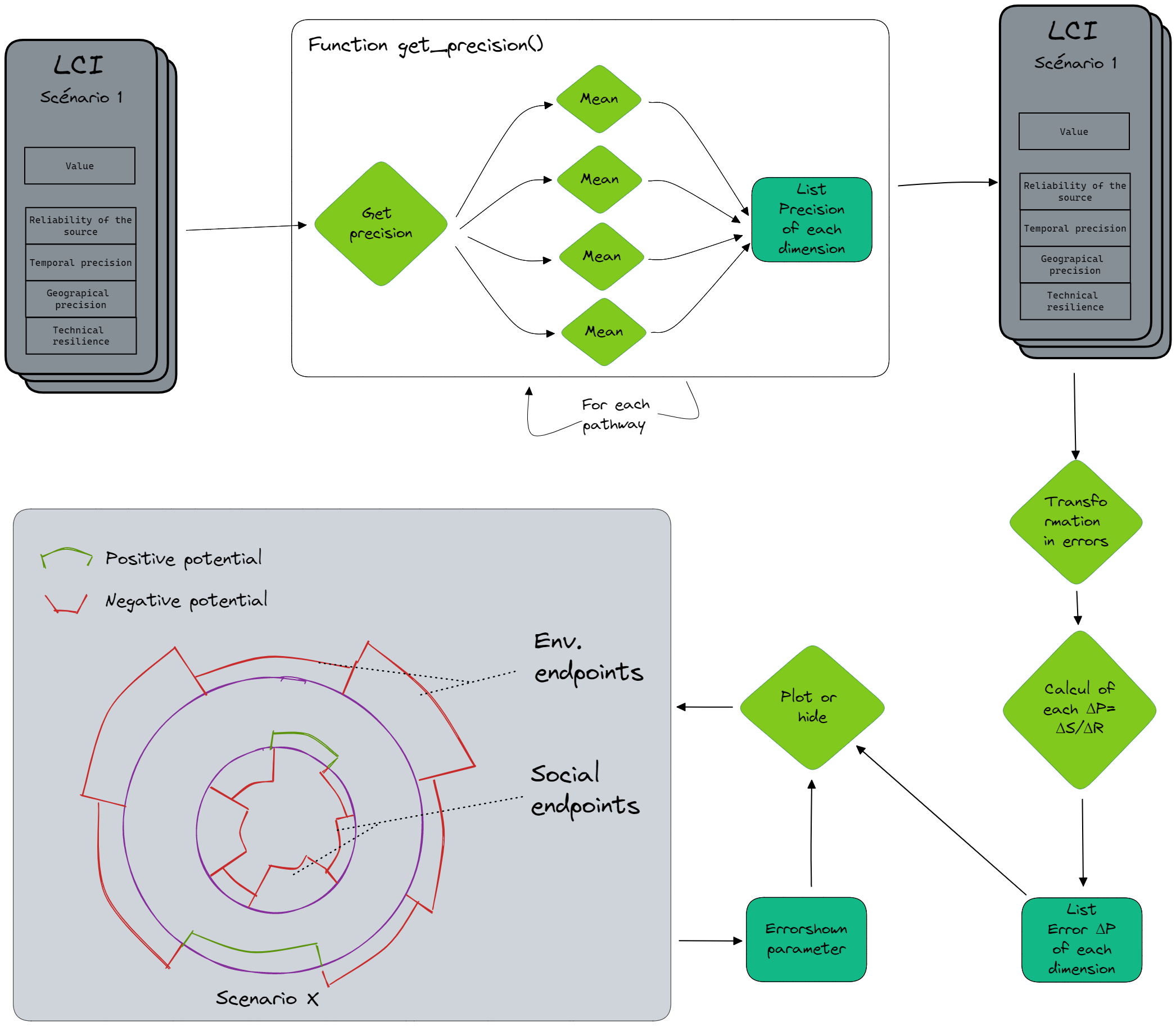
Image 3: Schéma de la méthode pour la gestion des précisions
Lors de l’étape d’évaluation des pathways, dans get_pathway_list(), pour chaque pathway activé sera créer un objet de classe CreatePathway. Cet objet possède un attribut self.precision ainsi qu’une méthode get_precision(). La méthode est appelé juste après la création du CreatePathway, elle va lire les valeurs des précisions de chaque variable d’entrée du chemin, et va enregistrer dans self.precision une liste contenant la moyenne des valeurs de chaque dimension:
> Pathways.py
def get_precision(self, LCI_table):
x = [0, 0, 0, 0]
self.precision = x
for id_ in self.entry:
x[0] += int(LCI_table.loc[LCI_table['ID'] == id_, 'Reliability of the source (/5)'].iloc[0])
x[1] += int(LCI_table.loc[LCI_table['ID'] == id_, 'Temporal precision (/5)'].iloc[0])
x[2] += int(LCI_table.loc[LCI_table['ID'] == id_, 'Spatial precision (/5)'].iloc[0])
x[3] += int(LCI_table.loc[LCI_table['ID'] == id_, 'Technical performance (/5)'].iloc[0])
for y in range(0, len(x)):
self.precision[y] = x[y] / len(self.entry)
Ce choix ne suppose pas des relations de calcul linéaires pour chaque chemin, mais plutôt une approximation méthodologique. Un traitement plus poussé vient ensuite, afin de transformer ces scores de précision en marges d’erreurs. Ce traitement est effectué dans Assessement.py, dans get_comparison().
Le module de gestion des incertitudes fonctionne en plusieurs étapes :
Importer les données
Transformation subjective des scores en incertitude. Pour une dimension donnée, un score de 5 correspond à 0% d’incertitudes, un 4 à 10%, un 3 à 20%, un 2 à 30%, un 1 à 40%, un 0 à 50%.
écarter les cas ou Vx et Vy sont nuls, si tel est le cas, l’incertitude est nulle.
Calcul de l’incertitude de scenario/référence selon la formule $\Delta P = P* \sqrt((\Delta X/X)²+(\Delta Y/Y))²$
# Gestion des incertitudes
nb_precision = len(pathway.precision)
DeltaP = []
x, y = pathway.precision, pathway_ref.precision
vX, vY = pathway.value, pathway_ref.value
for i in range(0, nb_precision):
# Moyenne des précisions des entrées par type
DeltaP.append(0)
# Transformation en incertitude (Subjectivement) et calcul de l'incertitude de f(X) = X/Y
Dx, Dy = (1 - (x[i] / 10 + 0.5)) * vX, (1 - (y[i] / 10 + 0.5)) * vY
DeltaP[i] == pathway.realisation * abs(pathway.value_n)
if vX == 0:
if vY != 0:
DeltaP[i] = pathway.realisation * abs(pathway.value_n) * Dy / vY
if vY == 0:
if vX != 0:
DeltaP[i] = pathway.realisation * abs(pathway.value_n) * Dx / vX
if vX != 0 and vY != 0:
DeltaP[i] = pathway.realisation * abs(pathway.value_n) * sqrt((Dx / vX)**2 + (Dy / vY)**2)
Le $\Delta$P ainsi obtenu est une liste contenant l’incertitude de la valeur au regard de la dimension de précision étudié. Dans sa version alpha, il n’y avait pas volonté à agréger les 4 dimensions de précision. L’introduction de la variable error_shown (dont la valeur est socké dans la classe Parameters(), et qui pourra être modifié dans l’interface graphique) permettra de choisir l’affichage des incertitudes, et laisse la souplesse d’intégrer une méthode de comparaison des différentes dimensions. Pour le moment, c’est l’incertitude issue de la précision de fiabilité de la source qui est représenté.
# On a 4 precisions pour chacune des catégories de précision, on affiche celle de error_shown.
pathway.precision = DeltaP[error_shown]
Lors de l’étape d’agrégation, dans Assessment.py, plus loin dans get_comparison(), la relation de calcul est linéaire, alors l’incertitude d’une catégorie d’Endpoint est l’image des incertitudes associés à chaque Endpoint par la même fonction:
$\Delta P = \Sigma_i \Delta P_i * weight_i$
Au final, pour chaque catégorie d’Endpoint, on écrit la marge d’erreur ainsi calculée dans la colonne suivant l’impact réel sur les capabilités, dans le Dataframe pa.output, stocké dans l’atrribut self.output de l’objet de classe Parameters() qui caractérise l’interface graphique.
4.2.3 Affichage des marges d’erreurs
Dans l’affichage de type 1 Specific stakeholder, il est possible d’afficher les barres d’erreurs associés à chaque catégorie d’Endpoint. Cet affichage est régulé par les boutons Errorbars IN et ErrorBars OUT.
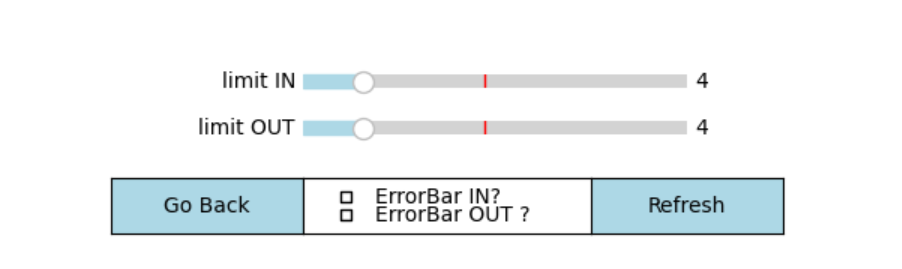
Image 4: Paramètres graphiques du Donut
Cet affichage est créé dans la fonction plot_type_1() de Graph.py, de la même manière que les autres boutons.
> Graph.py
> > plot_type_1()
ax_button_errorbar = plt.axes([0.2, 0.05, 0.15, 0.06], label='ErrorBar ?')
button_errorbar = CheckButtons(ax_button_errorbar, ('Errorbars IN', 'Errorbars OUT'), (False, True))
Le bouton button_errorbar, quand manipulé, appelle la fonction errorbar_check():
> Graph.py
> > plot_type_1()
def errorbar_check(val):
error = button_errorbar.get_status()
ax.clear()
limout = s_factor_out.val
limin = s_factor_in.val
ax.set_ylim(-limin, limout)
df_legend = database_output.loc[database_output['Stakeholders'] == stakeholder]
df_legend = df_legend[["Name", scenario_name]]
legend.table(cellText=df_legend.values, colLabels=df_legend.columns, loc='center', label='Table of values')
legend.grid(False)
legend.axis('off')
legend.set_title('Donut du projet (% de l\'objectif)',
loc='center', fontsize=20, ha="center", va="center", font="Bell MT")
plot_donut(database_output, ax, scenario_name, stakeholder, limin, limout, error, scenario_name + ':' + stakeholder)
fig.canvas.draw()
Ainsi, à chaque interaction, tout le processus plot_donut est appelé pour mettre à jour l’affichage. Le paramètre error de plot_donut est une liste de deux booléens (par exemple [True, False]) qui va indiquez dans une boucle conditionnelle si plot_donut doit ou non tracer des barres d’erreurs.
> Graph.py
> > plot_donut()
if error[1]:
ax.errorbar(ANGLES_OUT[mask_OUT_out], value_scenario_out[mask_OUT_out], yerr=error_out[mask_OUT_out],
capsize=4, capthick=4, color="red", linestyle='')
L’image du Donut avec les incertitudes ressemble à:

Image 5: Exemple de Donut affiché