2/ Installation & Guides
1/ Installation
Avant de commencer, vérifier que vous avez bien python d’installé sur votre ordinateur. Voici un tutoriel pour installer python.
1.1 Utilisation du fichier Run.sh
C’est la méthode la plus simple si vous n’êtes pas familier avec les lignes de commandes.
Commencez par télécharger en .zip le projet git depuis le dépôt Gitlab :
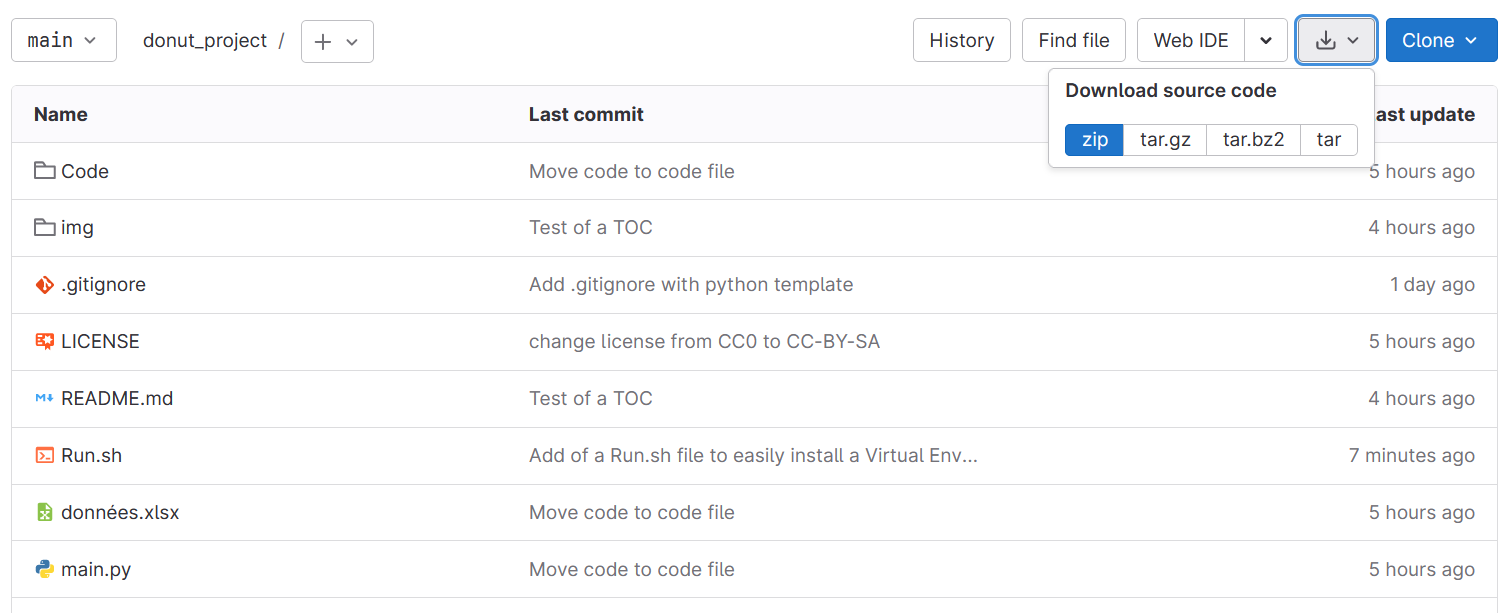
Image 1: Télécharger le projet
Extrayez ensuite le fichier zip dans le dossier de votre choix.
Ouvrez le dossier extrait. Cherchez le fichier Run.sh et double-cliquez dessus !
Attendez quelques secondes et… voilà, l’outil est prêt à être utilisé.
Le fichier Run.sh est prévu pour Windows. Pour Linux, suivez la méthode 1.2.
Si jamais rien ne se passe, il se peut que vous ayez besoin des droits d’administrateurs pour exécuter le fichier. Dans ce cas, nous vous recommandons la méthode 1.3 Utiliser un IDE.
1.2 Utilisation des lignes de commande (Windows)
Première étape : Installer Git
Si vous n’avez pas installé Git, assurez-vous de suivre le [tutoriel d’installation de Git] (https://git-scm.com/book/en/v2/Getting-Started-Installing-Git).
Deuxième étape : Cloner le projet
Vous êtes maintenant prêt à installer l’outil Donut.
Commencez par ouvrir un terminal dans le répertoire dans lequel vous voulez construire l’outil (Pour ce tutoriel, nommons-le chemin d’accès à votre dossier : your_path). Utilisez ensuite le code :
C:\your_path> git clone https://gitlab.com/eltr1/donut_project.git
Hop, le contenu du projet Gitlab de l’application Donut doit maintenant se trouver dans votre fichier your_path.
Troisième étape : Construire un environnement virtuel
Vous avez besoin d’un environnement virtuel avec des dépendances spécifiques (matplotlib, pandas…) pour faire fonctionner correctement l’outil.
Créons d’abord un environnement virtuel vierge à la racine du fichier :
C:\your_path> cd donut_project
C:\your_path\donut_project> py -m venv venv
Nous devons maintenant exécuter cet environnement virtuel à la racine du répertoire. Il faut activer le fichier activate.bat. Vous devriez obtenir quelque chose qui ressemble à la dernière ligne.
C:\your_path\donut_project> cd venv/Scripts
C:\your_path\donut_project\venv\Scripts> activate.bat
C:\your_path\donut_project\venv\Scripts> cd ..
C:\your_path\donut_project\venv\> cd ..
(venv) C:\your_path\donut_project>
Test rapide pour vérifier si pip est installé :
(venv) C:\your_path\donut_project> py -m ensurepip --upgrade
Maintenant, installons toutes les dépendances nécessaires à l’outil. Elles sont généralement stockées dans le document requirement.txt du projet Git. Il suffit donc de les installer en utilisant la ligne de code suivante :
(venv) C:\your_path\donut_project> py -m pip install -r requirement.txt
Et voilà ! L’outil Donut est complètement installé et prêt à l’emploi !
1.2 Utilisation des lignes de commandes (Linux)
Le raisonnement est similaire au tutoriel sous Windows, mais les lignes de codes sont légerement différentes:
C:\your_path> git clone https://gitlab.com/eltr1/donut_project.git
C:\your_path> cd donut_project
C:\your_path\donut_project> python3 -m venv venv
C:\your_path\donut_project> source venv/bin/activate
(venv) C:\your_path\donut_project> python3 -m ensurepip --upgrade
(venv) C:\your_path\donut_project> python3 -m pip install -r requirement.txt
Testé sur Mx linux (Debian 10).
1.3 Utilisation de l’IDE
Si vous n’êtes pas familier avec les lignes de commande, vous pouvez utiliser votre IDE préféré pour installer l’outil.
Pour cette tutoriel, nous utiliserons Pycharm Community. Mais cela devrait être similaire avec d’autres IDE. Si vous avez des problèmes pour cloner le dépôt git, cherchez un tuto pour votre IDE sur le web, il y en a beaucoup.
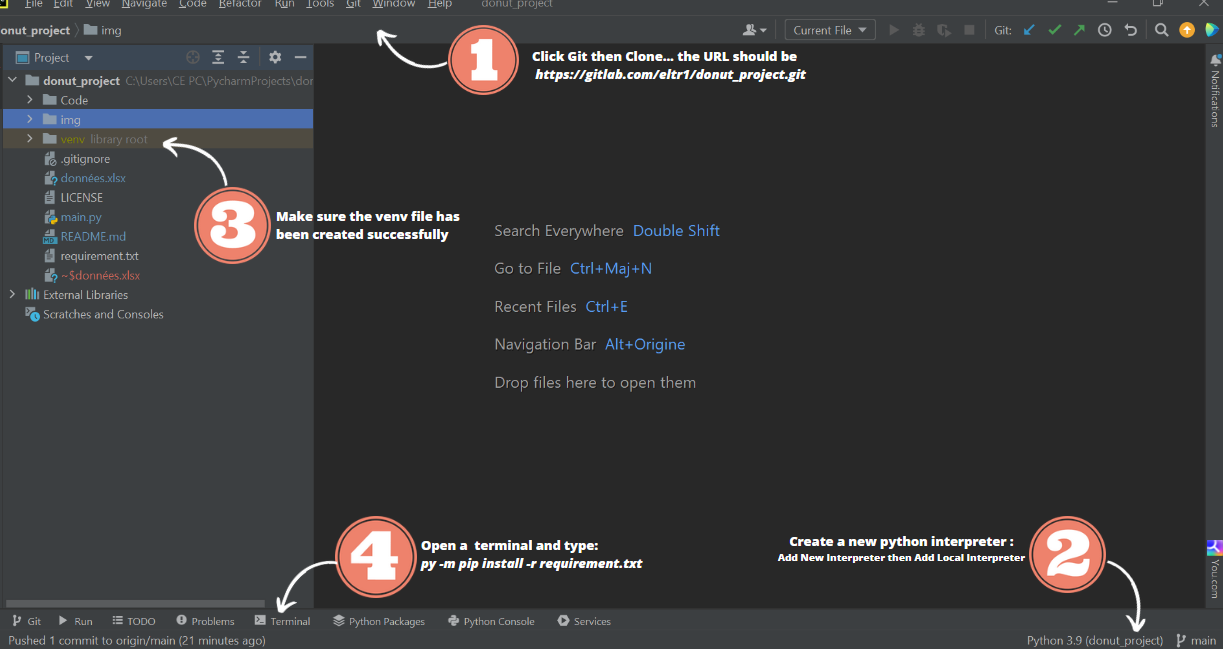
Image 2: Installation ave Pycharm Community
Première étape : Cloner le projet
Depuis le menu principal, sélectionnez
Git | Cloner, ou, si aucun projet n’est actuellement ouvert, cliquez surGet from VCSsur l’écran de bienvenue. Dans la boîte de dialogueGet from Version Control, spécifiez l’URL du référentiel distant que vous voulez cloner (rappelez-vous, pour l’outil Donut, l’URL esthttps://gitlab.com/eltr1/donut_project.git)Cliquez sur Cloner. Si vous souhaitez créer un projet basé sur les sources que vous avez clonées, cliquez sur Oui dans la boîte de dialogue de confirmation. Le mappage de la racine de Git sera automatiquement défini sur le répertoire racine du projet. Si votre projet contient des sous-modules, ils seront également clonés et automatiquement enregistrés comme racines du projet.
Deuxième étape : Configurer l’environnement virtuel
Configurez l’interpréteur python. Ouvrez Settings et cherchez projet, puis python interpreter. Vous pouvez aussi chercher l’interpréteur directement en faisant un clic gauche sur
Pyhton 3.9(en bas à droite de l’IDE) et Add a new interpreter, puis choisir de créer un interpréteur local.
Créez un nouvel interpréteur d’environnement virtuel, spécifiez le chemin vers la racine de l’outil, et conservez votre version de python dans l’interpréteur de base. Cela devrait prendre quelques secondes et un fichier venv devrait apparaître dans votre projet.
Troisième étape : Vérifier que vous êtes sur le bon environnement
Vérifiez simplement que le fichier venv est bien créer à la racine du projet. Vérifiez ensuite en bas à droite de votre IDE:
Le nom de de l’interpréteur doit être celui que vous avez créé en partie 2.
Quatrième étape : Installer les librairies
Ouvrez un terminal à la racine du projet dans votre IDE, puis installez toutes les dépendances en utilisant la commande :
(venv) PS C:\your_path\donut_project> py -m pip install -r requirement.txt
2/ Guide utilisateur
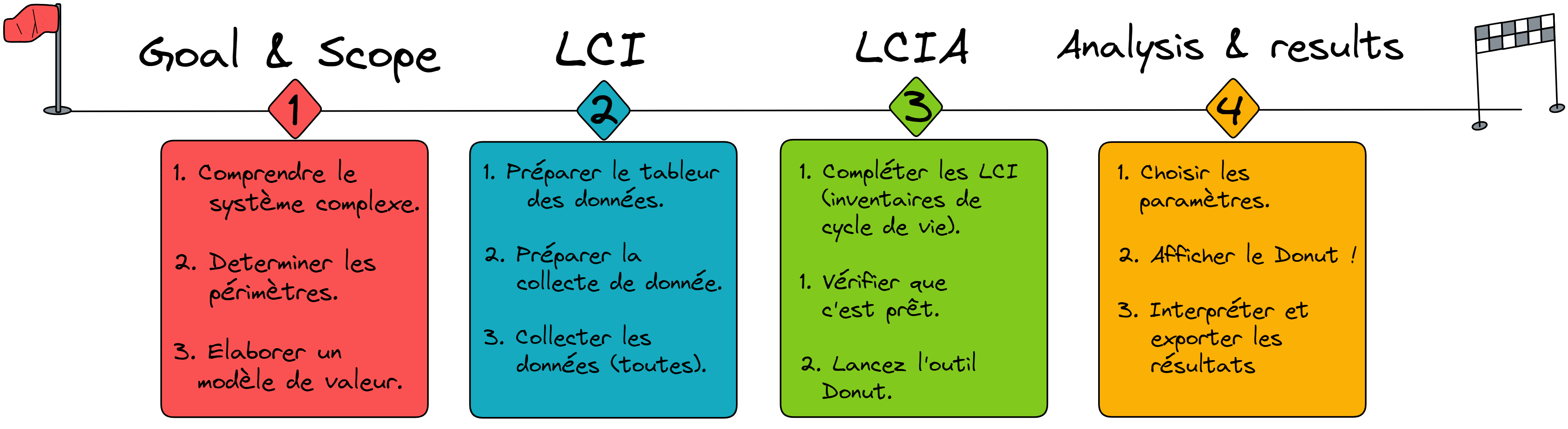
Dans cette partie, vous allez découvrir en 4 étapes comment utiliser pleinement l’outil Donut.
Avant de débuter, l’équipe vous invite à :
Vérifiez que vous avez bien suivi les étapes d’installations. - Lire le résumé de la méthodologie. - Se familiariser avec le jargon de la méthodologie, et de se référer au lexique au besoin.
Tout au long du guide, certains passages seront spécifiques à une application poussée de la méthodologie. Vous reconnaitrez ces paragraphes à la structure suivante.
Pour aller plus loin: …
2.1 Etape 1: Goal & Scope

2.1.1 Comprendre le système complexe
Il est primordial de bien connaitre l’environnement dans lequel va évoluer le projet. Cette première étape, dites Goal & scope a pour but d’amener les parties prenantes à une meilleure compréhension de leur projet, pour une meilleure application de la méthodologie développé pour l’application Donut. Puisque l’on ne peut pas évaluer un projet sans récolter de données, et qu’on ne peut récolter de données précises et sensibles sans définir les périmètres, parties prenantes impactées, biais de subjectivités du projet, il convient d’utiliser des outils pour déterminer chacun des points précédents.
Voici ci-dessous une proposition d’outils de design systémique[1] pour appréhender la complexité d’un système, et son ancrage contexto-spatio-temporel. Libre à vous de creuser leur méthodologie sur internet, et de vous former à en réaliser.
Pour aller plus loin: Ces outils de design se réalisent sous la forme d’ateliers participatifs animés par un designer-facilitateur connaissant les outils et la finalité de l’exercice. Il y a donc besoin de former une personne en interne ou bien de faire appel à un tiers compétent.

Tableau 1: Menus d'outils pour définir périmètres et objectifs
Les outils de design mentionnés dans les « Menus » sont détaillés dans ces tableaux :
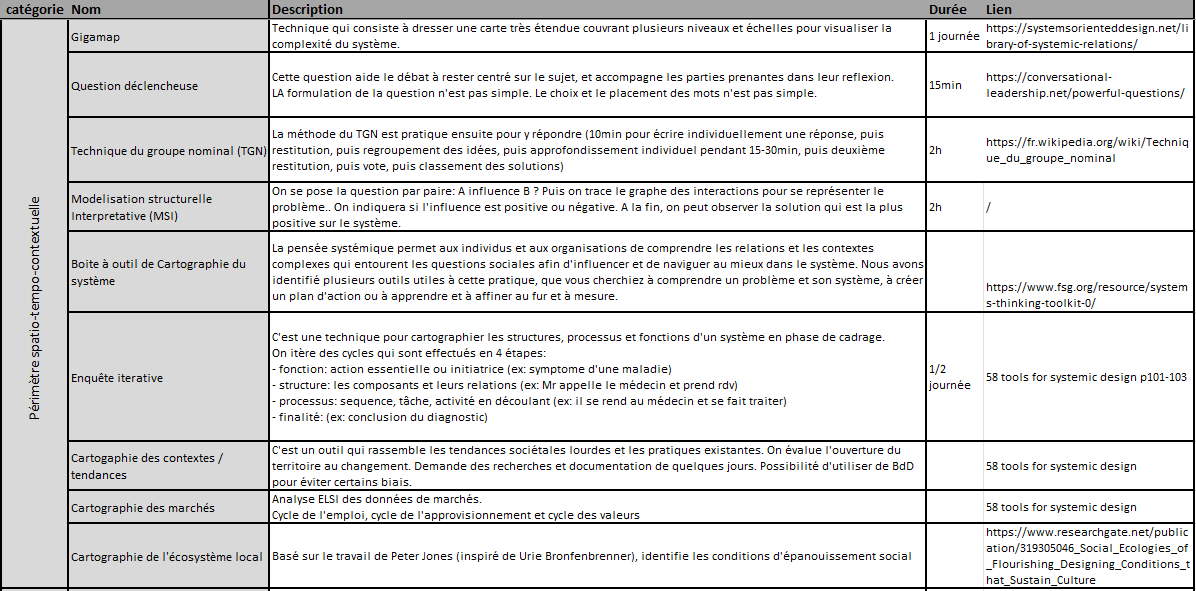
Tableau 2: Les outils liés aux périmètres

Tableau 3: Les outils liés aux indicateurs
2.1.2 Déterminer les périmètres
Les outils utilisés en partie 2.1.1 doivent être animé par des personnes qui portent un regard « collecte d’information ». Une majeur partie des informations concernant les périmètres émergera pendant les ateliers. Il faut les réaliser avec la vision des 3 dimensions de l’information : contexte, localité et temporalité.
Ce sont sur ces dimensions qu’il convient de poser un périmètre pour le projet.
Pour aller plus loin:
Le périmètre contextuelle du projet comprend :
Les parties prenantes impactées, les tendances, la sensibilité au changement, la fermeture du contexte, la situation géo-politique, la situation culturelle et institutionnelle. Le périmètre temporel comprend :
*L’étude des projections, politiques, objectifs futurs
L’étude de ce qui est en cours ou de ce qui s’est passé dans le périmètre contextuelle et géographique.
La temporalité d’impact (court, moyen, long terme)* Le périmètre de localisation comprend :
*Tout ce qui tourne autour des territoires sur lesquelles se trouvent les parties prenantes impactées.
Le niveau d’impact (direct, indirect, système)*
Plus les exercices sont approfondis, plus la formalisation des périmètres sera précise, et plus l’information récolté sera représentative.
2.1.3 Elaborer un modèle de valeur
Le modèle de valeurs sert de représentation pour les principes, l’éthique, la responsabilité et l’ancrage que l’on souhaite donner au projet. Ces modèles sont plus ou moins subjectifs et complet. Le modèle de valeurs traduit une ou des aires de protections (AoP) qui sont intrinsèquement liées à une amélioration de la qualité de vie d’un groupe social identifié.
Déterminer le modèle de valeurs est nécessaire pour fixer le cadre éthique du projet Cela permet de définir une liste d’indicateurs Endpoints, qui utilisent un certain nombre chemins, qui demandent un certain nombre de variables. On remonte ainsi jusqu’au cycle de vie du projet.
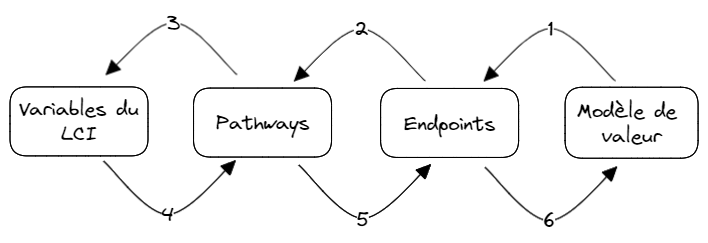
Dans la plupart des projets, déterminer le modèle de valeur se résume à utiliser un modèle de valeur existant, ou utilisé dans un ancien projet, et partagé à la communauté sur le GitLab de l’application Donut. Vous pourrez en trouver dans le dossier exemple à la racine du projet.
Pour aller plus loin: Pour les projets les plus ambitieux, il est possible d’établir son propre modèle de valeur. Pour cela, l’équipe peut partir de zéro ou bien d’un modèle existant et le modifier. Voir la partie Modèle de valeur, 2.3 Proposition de modèle de valeur pour un exemple illustrant une méthodologie de création de modèle de valeur.
2.2 Etape 2 : LCI
2.2.1 Préparer le tableur des données
Cette étape demande d’être familier avec la structure des bases de données. Ensuite, vous pouvez ouvrir l’un des tableurs de l’outil (format .ods pour Openoffice, LibreOffice ou .xlsx pour excel) ou bien créer votre document sur votre application de tableur préféré !
Commencez la lire la page 0.README: elle rappelle et complète certains points énoncés ici.
Préparations préliminaires :
Dans la page database_endpoint_impact, remplir le modèle de valeur (ou utilisez un modèle déjà existant) pour satisfaire l’éthique et les objectifs de l’étude que vous réalisez.
Dans la feuille pathway_data, vérifier le bon fonctionnement des formules dans TOUTE la colonne Activate. La case activate vaut 1 si le pathway est utilisé dans le modèle de valeur, 0 sinon.

Image 3: Activate, dans la feuille pathway_data
Si les fonctions ne marchent pas, il faut activer et désactiver les chemins à la main. Pour chaque chemin, rechercher si son identifiant apparait dals la colonne Pathway de la feuille database_endpoint_impact, si le chemin apparait, mettre 1, sinon 0.
Si vous êtes sur Libreoffice Calc, sur une version antérieure à 5.2, les fonctions ne marcheront pas.
De même, vérifier le bon fonctionnement des fonctions dans TOUTE la colonne Needed de la feuille TEMPLATE. Si la fonction ne marche pas, corriger pour retourner 1 quand l’identifiant de la variable figure dans la colonne Entry_ID de pathways_data, et 0 sinon.

Image 4: Colonnes Needed et Data Ready, dans TEMPLATE
Dans TEMPLATE, utiliser un filtre pour n’afficher que les variables qui sont nécessaire (avec un 1 dans la colonne Needed)
Préparer les feuilles pour les scénarios :
Dupliquer la page TEMPLATE autant de fois que de scénarios pour le projet.
Renommer la feuille de chaque scénario pour qu’elles commencent par SCENARIO. Par exemple, la feuille du scénario test est renommée en SCENARIO-test.

Image 5: Nom des feuilles
2.2.2 Préparer la collecte de donnée
Maintenant que le tableur est prêt :
Prendre une première fois connaissance des données. Prendre connaissance du type d’information demandé (valeur ou appréciation/dépréciation).
Préparer des sondages à transmettre aux parties prenantes. Préparer des réunions de travail si nécessaire.
Planifier les grandes étapes de la collecte : de plusieurs jours à plusieurs mois. Sur quels territoires se rendre ? Qui interviewer ? Quels ouvrages lire pour s’inspirer des méthodologies de relève de données ?
On distingue deux types d’informations en concept systémique :
Information structurante : incluse dans les mémoires du système (ex ADN dans cellule)
Information circulante : présente au sein des échanges entre les systèmes et au sein des systèmes.
Dans les démarches de collecte, prévoir la récolte de ces deux types d’informations. Enfin, il convient de se préparer à relever la précision de chaque donnée. La précision d’une donnée est définie sous 4 dimensions :

Tableau 4: Notation de la précision
Le projet possédant plusieurs scénarios, il convient d’identifier des points de vigilances sur les zones de différenciation des scénarios. La collecte doit récupérer des données pour chaque scénario. Dans certains cas, la valeur peut-être la même, mais pas la précision. Par exemple, si pour un scénario, il n’est pas possible de relever la donnée, il peut être jugé pertinent de prendre le même ordre de grandeur qu’un scénario similaire sur ce point, mais avec une précision Reliability of the source plus faible.
Voici un cours inventaire de question pour évaluer le non marchand :
Effet sur les ressources de financement ?
Effet sur le développement local ?
Effet sur les ressources publiques ?
Effet sur l’équilibre extérieur ?
Effet sur le chômage et la pauvreté ?
Effet sur les écosystèmes ?
Effet sur les ressources naturelles ?
Effet sur la santé humaine ?
Effet de l’éducation sur la production et la productivité ?
En comparant l’apport de la situation initiale avec la situation alternative, il faut se poser la bonne question puis établir le niveau d’appréciation/dépréciation.
2.2.3 Collecter les données (toutes)
Pour satisfaire les axiomes de subjectivité et diversité, il y a besoin de multiplicité des méthodes (conforter des résultats, diversifier les regards, déterminer le seuil de saturation théorique.). Il convient alors de croiser les résultats avec une méthode de triangulation jugée pertinente.
Plusieurs méthodes de collecte d’information sont à mener sur site :
Observer les faits (selon le cadre POEMS - Personnes Object Environnement Message Services), relever ainsi ce que le déclaratif ne permet pas d’exprimer : comportements routiniers, reflexes ou intériorisés. On consigne tout.
Interview (méthode QQOQCC) pour collecter le contexte, la culture, les activités, messages ; temporalités, social. Il faut avoir une posture d’écoute active et faire preuve de neutralité et d’intérêt.
Questionnaires ou sondage si interview pas possible.
Récolte sur des documents internes au projet (PLU, programme, études techniques spécifiques, résultats d’ateliers antérieurs).
Récolte des données issues des ateliers de compréhension du système et des périmètres.
Récolte sur des bases de données libres et consultables[2] :
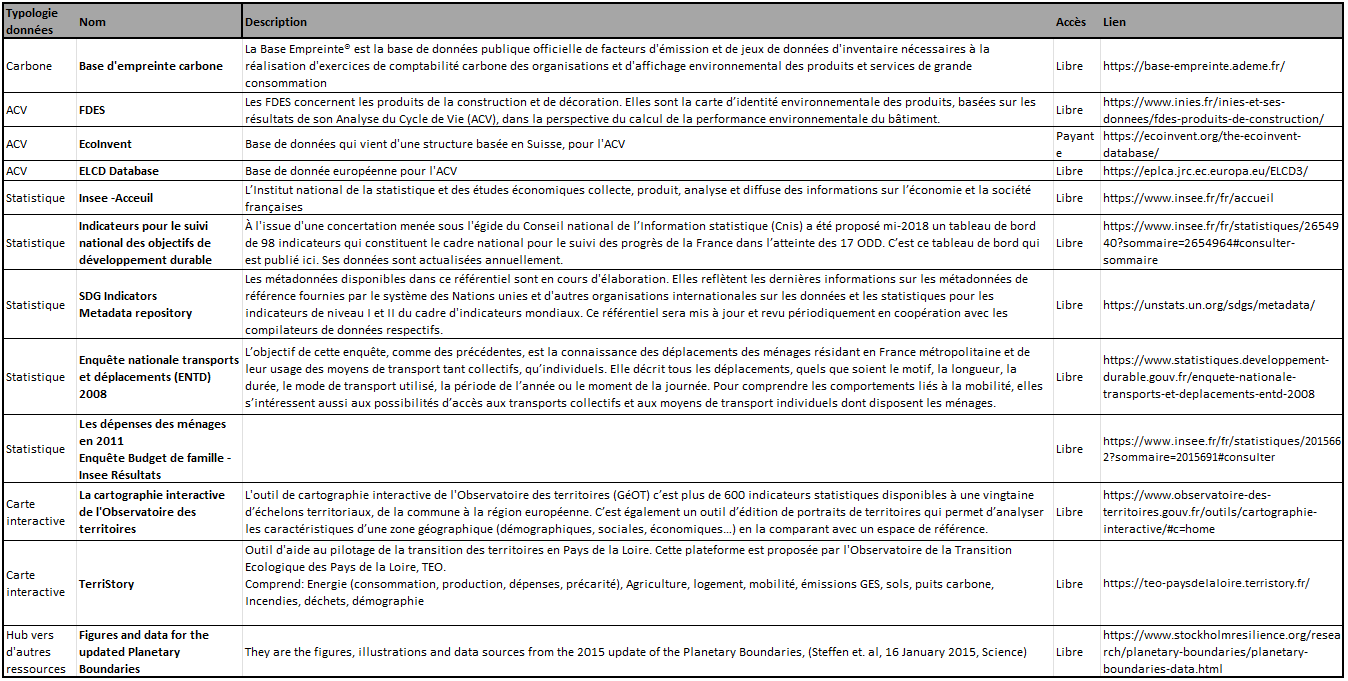
Tableau 5: Extrait des bases de données libres et consultables
Récolte de données sur d’anciens projets.
Exploitation des bilans comptables, en y ajoutant des données économiques. Limites: réussir à scinder quel part va à quelle activité est délicate, pas de tests de sensibilité fiables)
Evaluation de l’itinéraire technique. Travail documentaire pour identifier, quantifier, monétariser tout à leur coût unitaire économique chacun des éléments techniques
Si des informations sont jugées trop compliqués à récupérer, il convient soit de faire confiance à un expert pour étudier et estimer les données, soit d’estimer soit même. Bien noter les précisions relatives à chaque donnée.
2.3 Etape 3: LCIA

2.3.1 Compléter les LCI
Toutes les données sont récoltées. Que ce soit sur des rapports de réunions, sur les résultats d’un sondage ou une vidéo d’un entretien, il convient de transcrire toutes ces données sur le tableur qui a été préparer.
Pour chaque scénario, remplir les feuilles correspondantes.
2.3.2 Vérifier que c’est prêt
Vérifier que chaque feuille scénario est prête. Si la page est prête, c’est que la case Excel ready est égale à 1 (ici en vert).
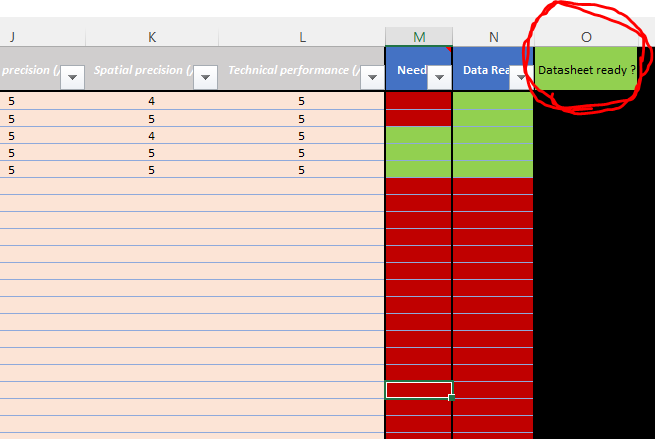
Image 6: Datasheet ready ? Dans TEMPLATE
Si ce n’est pas le cas, vérifier les colonnes Needed et Data ready:
Pour une variable (ligne), si la case Needed est égale à 1 (ici colorié en vert), alors la case Data ready doit être égale à 1 (ici colorié en vert).
Si ce n’est pas le cas, vérifier les formules.
2.3.3 Lancez l’outil Donut
Pour lancez l’outil Donut, plusieurs possibilités selon la méthode d’installation que vous avez suivi :
Exécuter le fichier Run.sh marche toujours.
Dans un IDE, après avoir suivi les étapes d’installation, lire le fichier main.py .
En ligne de commande, après avoir suivi les étapes d’installations, tapez
py main.py.
2.4 Etape 4: Analyse et résultats

2.4.1 Choisir les paramètres
La fenêtre est divisé en quatre parties :
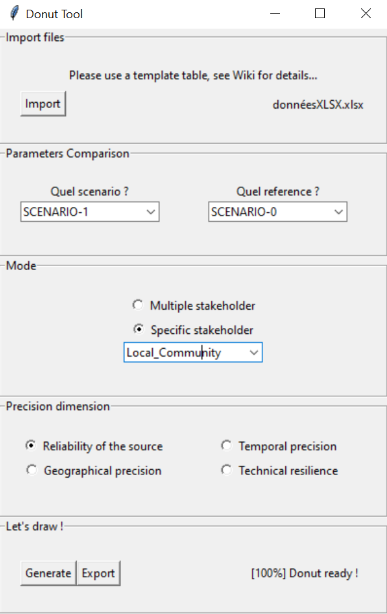
Image 7: Menu de l'application Donut
Importer le tableur des bases de données avec le bouton Import. Ce bouton ouvre une fenêtre du navigateur de fichier et laisse l’utilisateur trouver et sélectionner celui-ci. Si le fichier est bien importé, son nom doit apparaitre à la droite du bouton.
Choisir le scénario à étudier dans la liste déroulante Quel Scénario ?
Choisir la référence dans la liste déroulante Quelle référence pour la comparaison ?
Choisir le mode souhaité. L’utilisateur à le choix entre Multiple stakeholder et Specific stakeholder. Dans le cas de Specific stakeholder l’application tracera alors le Donut qui correspond aux impacts sur cet catégorie de partie prenante. Dans le cas du multiple stakeholder, l’application trace sur la même image 5 Donuts, un pour chacune des parties prenantes.
Et voilà ! Vous êtes fin prêt !
2.4.2 Afficher le Donut !
Il ne vous reste plus qu’à cliquer sur Generate ! Si tout se passe bien, alors votre Donut va s’afficher à la fin du chargement.
S’il y a une erreur ou un problème :
Vérifier que vous avez bien compléter les bases de données dans le tableur.
Vérifier que le nom des feuilles des scénarios commence bien par SCENARIO.
Vérifier les noms des feuilles pathway_data et database_endpoint_impact.
Si le problème persiste :
Changer de mode d’installation. Privilégiez une installation en ligne de commande ou en IDE.
Vérifier qu’un fichier /venv/ est bien apparu à la racine de votre projet (au même niveau que main.py ou Run.sh dans votre gestionnaire de fichier).
Ré-installer toutes les librairies nécessaires dans votre environnement virtuel :
C:\your_path\donut_project> cd venv/Scripts
C:\your_path\donut_project\venv\Scripts> activate.bat
C:\your_path\donut_project\venv\Scripts> cd ..
C:\your_path\donut_project> py -m pip install -r requirement.txt`
Si le problème persiste, relancer l’outil depuis un IDE comme Pycharm ou Spider. Vous avez ainsi accès à une console qui explique le détail du crash.
Si le problème persiste encore (c’est possible), reporter l’erreur dans la rebrique « Issue » du Gitlab du projet.
2.4.3 Interpréter et exporter les résultats
Le Donut s’affiche !
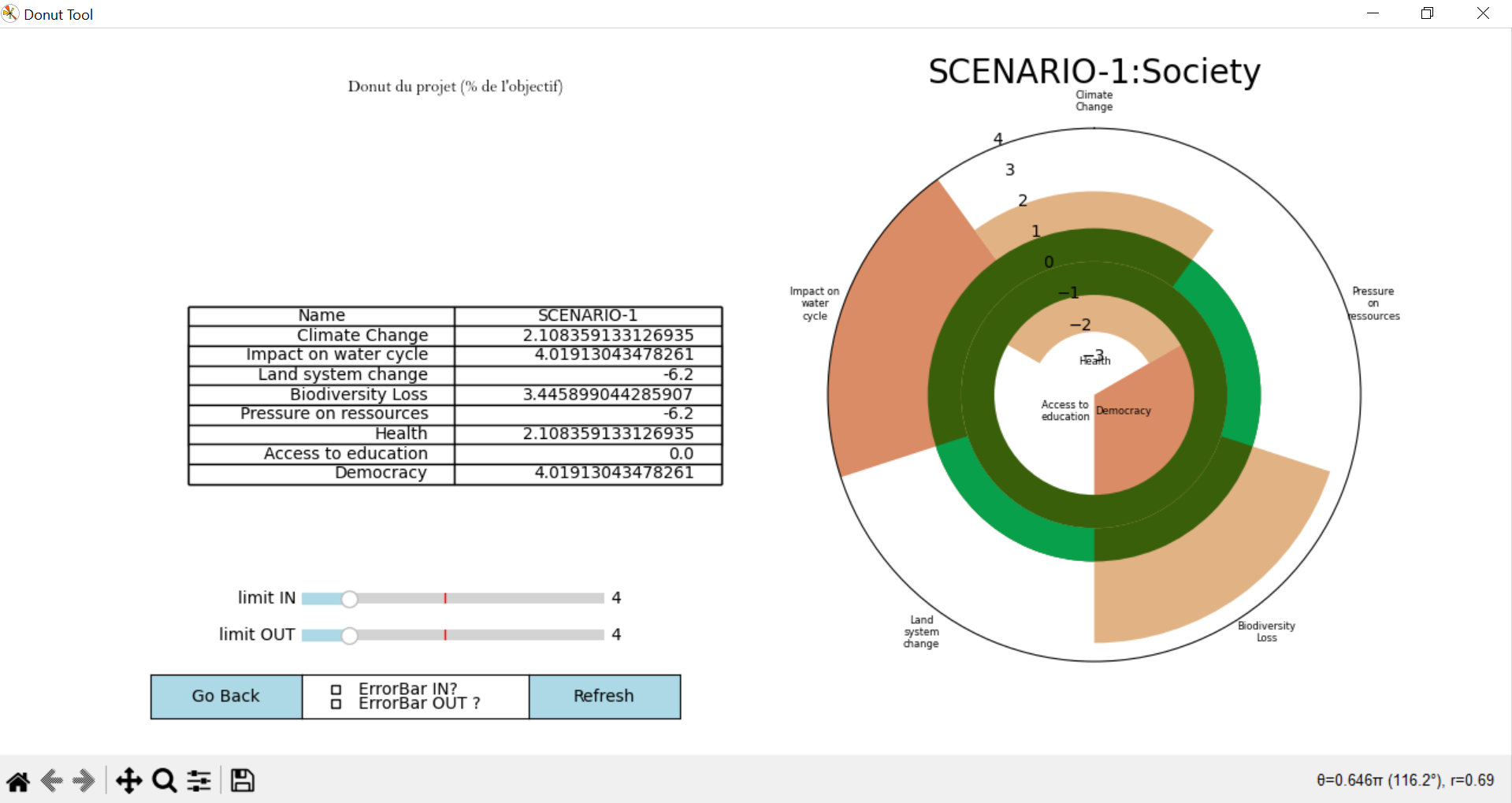
Image 8: Affichage du Donut
Quelques boutons sont à votre disposition :
Go back vous permet de fermer l’image.
Refresh recharge le graphique du Donut en cas de bug d’affichages (bugs réguliers dans la version alpha, dès que l’on manipule lim IN et lim OUT aux extrêmes.)
Les sliders lim_IN et lim_OUT permettent de modifier l’échelle intérieur et extérieur du Donut.
Le tableau à gauche est un récapitulatif de graphique Donut.
Pour récupérer les données, utilisez le bouton Export sur l’interface graphique des paramètres (voir 2.4.1). Un fichier s’enregistre alors à la racine du projet.
3/ Guide contributeur —-
Le guide contributeur a pour objectif de clarifier quelques manipulations simples qui demandent de plonger dans les profondeurs de l’outil. Il s’adresse à ceux qui veulent enrichir les bases de données de l’outil. Le guide donne aussi quelques pistes de réflexions pour améliorer l’outil, afin que ceux qui se sentent inspirés, voir animés par un sentiment divin, puissent contribuer à l’outil.
3.1 Implémenter un nouveau pathway
Je t’invite à lire la partie Evaluation_pathway pour comprendre ce qu’est un pathway, et comment ils sont manipulés dans l’outil. La création d’un nouveau pathway s’effectue alors en 3 étapes. Avant de débuter, assures-toi que tu connais bien les caractéristiques de ton pathway ainsi que de la relation de calcul reliant tes entrées à ta sortie.
Etape 1 : La base de données pathway_data.
Dans la version alpha, tous les pathways sont stocké dans une base de données tableur, cela à l’avantage un accès et une navigation facile dans cette base de données. Seul le module de calcul est lui directement écrit dans le code python.
La création d’un nouveau chemin commence ainsi par l’ajouter dans la base de données des chemins :
Ouvrir votre tableur des bases de données de l’outil, et allez sur la page pathway_data
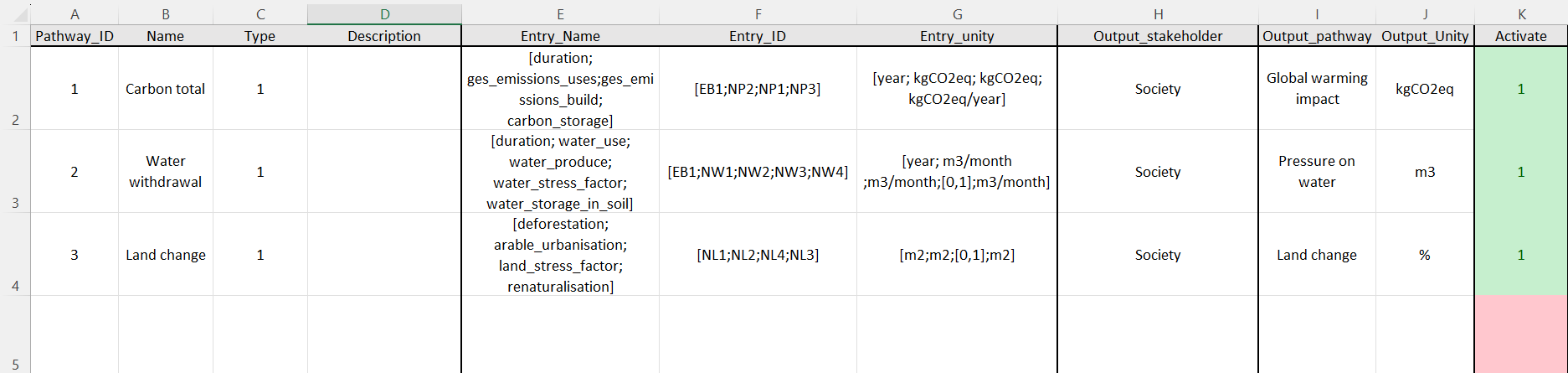
Image 9: page pathway_data
- Remplir une nouvelle ligne avec vos informations. Vérifier que l'ID que vous donnez à votre chemin est bien unique (les ID sont dans l'ordre croissant en général).Dans la colonne Type, deux choix s’offrent à vous : - Indiquez 1 si votre outil utilise une relation de type calcul(): mathématique ou statistique que vous pouvez écrire dans python. - Si votre relation utilise le type estimate(): des variables non quantifiables auxquelles vous attribuez une notation d’appréciation ou de dépréciation: - Choisir un modèle statistique pour la répartition des impacts (parmi ceux permis par l’algorithme) - Indiquez 2, nom_du_modèle dans la case Type. Par exemple 2, linear pour un modèle linéaire.
Etendre les formules de la colonne Activate si besoin
Etape 2 : Compléter la feuille TEMPLATE
Une fois pathway_data mis à jour, il convient de vérifier que toutes les entrées sont disponibles.
Dans la page TEMPLATE, naviguez pour essayer de retrouver les entrées de votre chemin (en cherchant leur nom, ou leur partie prenante, leur capital et sous-capital).
Si une entrée n’existe pas, créez-là. Remplissez les colonnes A à G.
Etape 3 : Compléter le code python
Si le type du chemin est 1 :
Rendez-vous dans la fonction calcul() dans Pathways.py:
Là, il vous suffit de rajouter une nouvelle boucle if pour votre chemin. La boucle If regarde l’identifiant du chemin, puis entrez vos relations de calculs. Les entrées sont stockées en début de fonction dans un dictionnaire. Ainsi vous pouvez appeler la valeur de votre entrée_1 avec e[“entrée_1”].
Voici ci-dessous un extrait du code avec un exemple de création de pathway.
> Pathways.py
def calcul(self, LCI_table):
# Value attribution - généralisé
e = {}
for i in range(0, len(self.entry)):
e[self.name[i]] = get_values(LCI_table, self.entry[i])
if type(e[self.name[i]]) == str:
e[self.name[i]] = float(e[self.name[i]])
# Name: Global warming impact / ID:1
if self.ID == 1:
self.value = e['ges_emissions_build'] + e['ges_emissions_uses']
self.value += - e['duration'] * float(e['carbon_storage'][1])
...
# Your new pathway
if self.ID == your_ID:
x = do your calcul
x' = x + e['entrée_7'] / e['entrée_5']
self.value = x'
Si le type de chemin est 2 :
Rendez-vous dans la fonction estimate_statistical() dans Pathways, et vérifiez que le modèle de statistique de votre nouveau chemin est bien définit.
3.2 Implémenter un nouveau modèle de valeur
Familiarisez-vous avec la page modèle de valeur.
Dans cette partie, nous expliquons comment traduire ce modèle pour l’outil, nous parons donc du principe que vous possédez déjà ce modèle.
Tout se passe dans le tableur, dans la feuille database_endpoint_impact, donc soyez à jour sur sa structure.
Pour chaque catégorie de partie prenante, remplissez les lignes suivantes du tableau.
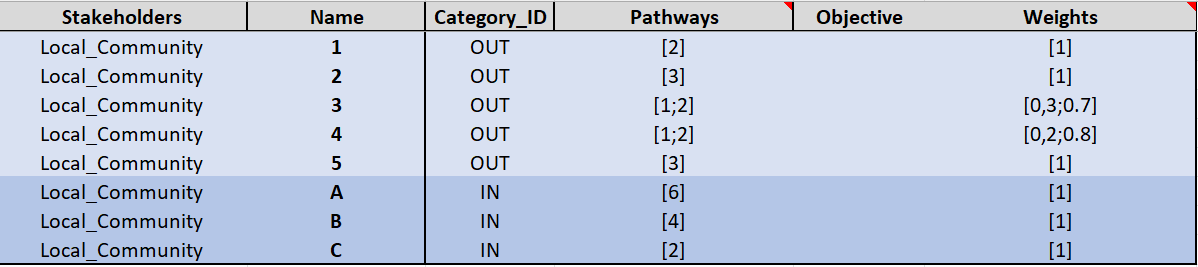
Tableau 6: Feuille database_endpoint_impact
Quelques précisions :L’algorithme lit la base de données dans l’ordre, et trace le Donut dans le sens des aiguilles. Ainsi les lignes les plus hautes seront affichées vers 1h sur le Donut, et les lignes les plus basses vers 11h.
Le poids total d’une ligne doit être égale à 1.
Vérifiez que les Pathways sont bien créés. Ce sont leurs identifiants qui sont entre crochet, et séparer par « ; ».
Dans Category_ID, indiquez OUT ou IN selon la représentation des AoP choisit. Dans le cas de 3 AoP, par exemple pour le modèle RAH (Resilience, Autonomy, Harmony), on peut choisir la représentation suivante :
Résilience : OUT
Autonomy : IN, et on conviendra de mettre toutes ses lignes AVANT harmonie, afin qu’elles soient tracées sur la partie intérieur droite du Donut…
Harmony : IN, et on conviendra de mettre toutes ses lignes APRES autonomy, afin qu’elles soient tracées sur la partie intérieur gauche du Donut…
Dans objective, rentrer des valeurs d’impacts réels souhaité par une politique (exemple : 100% de sentiment de sécurité, 99% de personnes avec logement stable, 2% de pertes énergétiques…). Rentrer ces valeurs dans la ligne correspondante. Cette information permet de forcer la comparaison des sorties d’un chemin. Au lieu de comparer avec la valeur d’un scénario de référence, on compare avec la valeur entrée ici. Cela permet de forcer la comparaison avec les résultats souhaités d’une politique locale ou régionale, ou d’un objectif du programme.